












java学习笔记下
点击按钮,AI 将为你生成这篇文章的摘要
异常
初识
初识
异常(Exception) 是指程序在运行过程中出现的错误情况,这些错误可能导致程序的正常流程中断。异常可以是由程序自身的逻辑错误引起,也可以是由外部因素(如文件未找到、网络中断等)导致。
层级结构
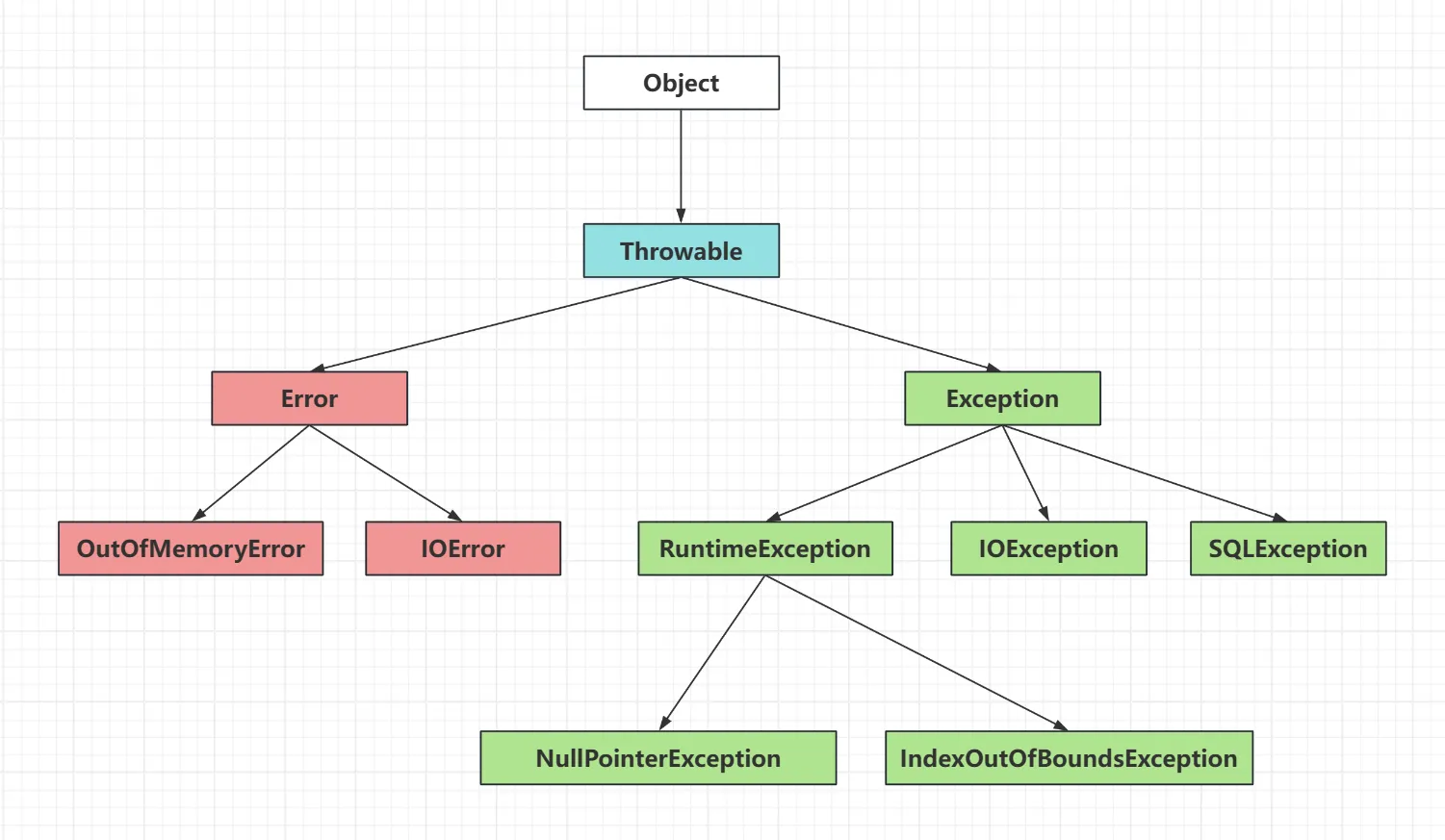
Error(错误) 描述:错误通常指的是由Java虚拟机(JVM)自身引起的严重问题,这些问题往往超出了程序的控制。错误通常无法通过程序代码来恢复,因此是不建议进行捕获和处理的(虽然它们可以写在 catch 后的括号中)。 示例:常见的错误有 OutOfMemoryError(内存不足)、StackOverflowError(栈溢出)和 NoClassDefFoundError(类定义未找到)。 处理建议:对于错误,通常不需要程序员处理,发生后程序很可能会直接终止。正确的做法是优化代码以避免这些错误的发生。
Exception(异常) 描述:异常是程序运行过程中可以被捕获并处理的问题。当程序遇到异常时,可以通过适当的处理机制(如 try-catch 块)来防止程序崩溃。 分类: 检查型异常(Checked Exceptions):又名,编译时异常
描述:检查型异常是在编译时被检查的异常。程序员必须在代码中进行处理,否则编译器会报错。它们通常表示外部环境的问题,如文件未找到、网络连接失败等。 示例:IOException(输入输出异常)、SQLException(SQL异常)、ClassNotFoundException(类未找到异常)。 处理方式:使用 try-catch 块捕获异常,或在方法签名中使用 throws 声明该异常。 非检查型异常(Unchecked Exceptions):又名,运行时异常
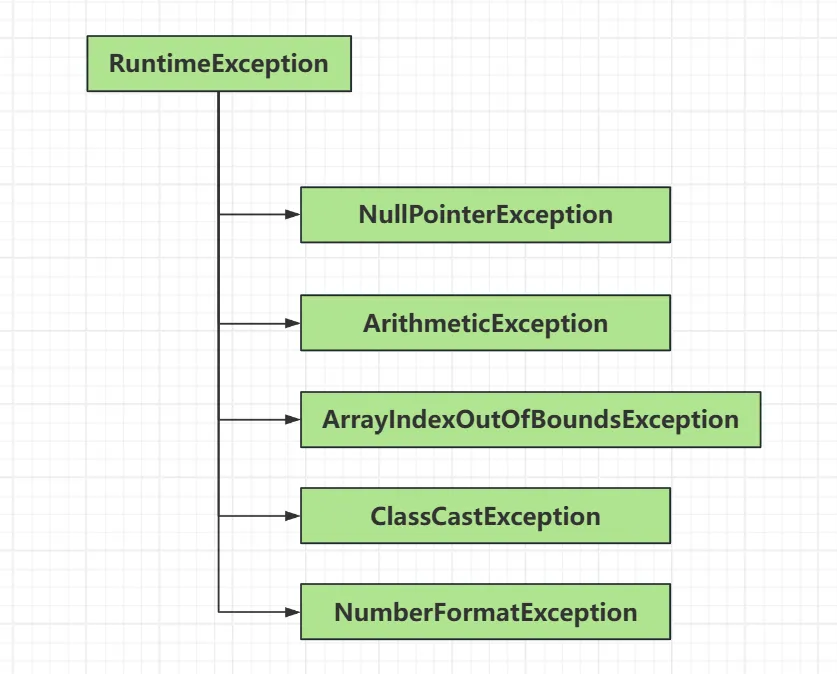
描述:非检查型异常是在运行时发生的异常,它们通常是由程序的逻辑错误引起的,如数组越界、空指针引用等。编译器不会强制要求程序员处理这些异常。 示例:NullPointerException(空指针异常)、ArrayIndexOutOfBoundsException(数组下标越界)、IllegalArgumentException(非法参数异常)。 处理方式:虽然不强制要求捕获,但建议在适当的地方进行处理,以提高程序的健壮性。
运行时异常
运行时异常
1.NullPointerException 空指针异常
当应用程序试图使用 null 作为对象的引用时,会抛出 NullPointerException。这通常发生在尝试访问对象的方法或属性时。
public class Example { public static void main(String[] args) { String str = null; System.out.println(str.length()); // 尝试使用空引用 }}ArithmeticException 数学运算异常
当发生算术运算的异常情况时,会抛出 ArithmeticException。最常见的情况是除以零。
public class Example { public static void main(String[] args) { int result = 10 / 0; }}ArrayIndexOutOfBoundsException 数组下标越界异常
当尝试访问数组中不存在的索引时,会抛出 ArrayIndexOutOfBoundsException。该异常表示访问的索引超出了合法范围(0到数组长度-1)。
public class Example { public static void main(String[] args) { int[] arr = new int[5]; System.out.println(arr[-1]); }}ClassCastException 类型转换异常
当尝试将对象强制转换为不兼容的类型时,会抛出 ClassCastException。这通常发生在使用类型转换时。
public class Example { public static void main(String[] args) { Object obj = new String(); Integer num = (Integer)obj; }}NumberFormatException 数字格式不正确异常
当尝试将字符串转换为数字格式时,如果字符串的格式不符合数字的要求,就会抛出 NumberFormatException。例如,尝试将一个非数字字符串转换为整数。
public class Example { public static void main(String[] args) { String str = "abc"; int num = Integer.parseInt(str); }}编译时异常
1、SQLException SQLException 是在与数据库交互时可能发生的异常。它可以指示由于数据库访问错误或其他数据库问题(如查询语法错误、连接失败等)而导致的错误。
2、IOException IOException 是与输入/输出操作相关的异常,例如文件读取或网络通信时出错。它是处理文件和流操作时的常见异常。
3、FileNotFoundException FileNotFoundException 是 IOException 的一个子类,在尝试打开一个不存在的文件时抛出。它通常在文件操作时进行检查。
4、ClassNotFoundException ClassNotFoundException 是当应用程序尝试通过字符串名称加载类,但没有找到对应类时抛出的异常。这通常发生在使用反射或动态加载类时。
5、EOFException EOFException 是在读取文件时遇到文件末尾(End of File)而未能成功读取数据时抛出的异常。通常在使用数据 [MySQL 8.0 Command Line Client.lnk](C:\Users\LYF\Desktop\MySQL 8.0 Command Line Client.lnk) 输入流(DataInputStream)时会遇到此异常。
捕获异常
try-catch 语句
try { int result = 10 / 0; // 可能抛出 ArithmeticException} catch (ArithmeticException e) { System.out.println("ArithmeticException: " + e.getMessage());}try-catch-finally语句
区别
finally块中的代码无论是否发生异常,都会执行,通常用于清理资源,如关闭文件或数据库连
对于 try-catch 语句和 try-catch-finally 语句是可以嵌套的
BufferedReader reader = null;try { reader = new BufferedReader(new FileReader("file.txt")); String line = reader.readLine(); System.out.println(line);} catch (IOException e) { System.out.println("IOException: " + e.getMessage());} finally { // 确保资源被释放 if (reader != null) { try { reader.close(); } catch (IOException e) { System.out.println("Error closing reader: " + e.getMessage()); } }}一个catch块捕获多个异常
可以在一个catch块中捕获多个异常,使用管道符号**|**分隔多个异常类型。这对于处理多个异常类型时执行相同的处理逻辑非常有用。
try { // 可能抛出异常的代码} catch (IOException | NullPointerException e) { // 处理 IOException 或 NullPointerException System.out.println("Exception: " + e.getMessage());}try-with-resources
初识
try-with-resources 语句用于自动管理资源(如文件流、数据库连接等),确保在 try 块结束时自动关闭资源,避免资源泄漏。
import java.io.BufferedReader;import java.io.FileReader;import java.io.IOException;
public class TryWithResourcesExample { public static void main(String[] args) { try (BufferedReader reader = new BufferedReader(new FileReader("file.txt"))) { String line = reader.readLine(); System.out.println(line); } catch (IOException e) { System.out.println("IOException: " + e.getMessage()); } // 无需显式关闭 reader,Java 会自动处理 }}注意点
1.可能出现异常的语句要放到 try 块中
只有放到 try 语句块中的代码抛出的异常才能被 catch 语句块捕获到。
2.在 try 块中的某一句代码抛出异常后,该异常被 catch 捕获,则会直接跳入 catch 语句块中执行。try 块的剩余语句不会再执行了。
public class Example { public static void main(String[] args) { try { int res = 1 / 0; System.out.println("..."); // 这一句不会执行 } catch(ArithmeticException e) { System.out.println(e.getMessage()); } }}3.没有发生异常或者没有捕获到异常,catch 块都不会被执行。
public class Example { public static int method() { try { String name = null; name.length(); } catch (NullPointerException e) { return 1; } finally { return 2; } }
public static void main(String[] args) { System.out.println(method()); }}//由于 finally 块无论是否发生异常都会被执行,所以在 catch 块中不会返回,到了 finally 块中才会返回,所以最终 method() 方法返回值为 2自定义异常
初识
自定义异常类通常需要继承 Exception 类(对于编译时异常)或 RuntimeException 类(对于运行时异常)。
可以根据需要为自定义异常类添加多个构造方法,以便于传递错误信息或其他相关信息
class AgeOutOfRangeException extends RuntimeException { public AgeOutOfRangeException(String message) { super(message); }
public AgeOutOfRangeException(String message, Throwable cause) { super(message, cause); }}自定义异常的使用
public class Example { public static void main(String[] args) { try { testAge(-1); } catch(AgeOutOfRangeException e) { System.out.println(e.getMessage()); } }
public static void testAge(int age) { if(age < 0) { throw new AgeOutOfRangeException("年龄要大于或等于0岁"); } }}
class AgeOutOfRangeException extends RuntimeException { public AgeOutOfRangeException(String message) { super(message); }
public AgeOutOfRangeException(String message, Throwable cause) { super(message, cause); }}抛出异常
初识throw
throw 是一个关键字,用于显式地抛出一个异常。它可以抛出任何类型的异常,包括自定义异常和Java内置异常。使用 throw 可以让开发者在特定条件下主动触发异常,从而能够进行异常的处理或传递。
抛出内置异常
public void checkNumber(int number) { if (number < 0) { throw new IllegalArgumentException("数字不能为负数"); }}抛出自定义异常
class InvalidAgeException extends Exception { public InvalidAgeException(String message) { super(message); }}
public class AgeValidator { public void validate(int age) throws InvalidAgeException { if (age < 18) { throw new InvalidAgeException("年龄必须大于或等于18岁"); } }}throws抛出异常
初识throws异常
用于在方法声明中表明该方法可能会抛出哪些异常,由调用者处理。它告诉方法的调用者需要准备处理这些异常,或将它们传播给更高级别的异常处理代码。
一般用于某个方法中的语句可能抛出异常,但是并不能确定如何处理这个异常,则通过 throws 显式声明这个方法可能抛出的异常,表示这个方法将不对这个异常进行处理,调用者需要处理异常。
public void myMethod() throws ExceptionType { // 可能抛出 ExceptionType 的代码 // 这里的 ExceptionType 可以是可能抛出异常的类型,也可以是其父类类型}
public static void foo() throws IOException, SQLException { // 可能抛出 IOException, SQLException 异常的语句 }抛出编译时异常
throws 一般声明方法可能抛出编译时异常,这些异常必须在方法内部或调用者中进行处理。
import java.io.BufferedReader;import java.io.FileReader;import java.io.IOException;
public class ThrowsExample {
public static void main(String[] args) { try { readFile("nonexistentfile.txt"); } catch (IOException e) { System.out.println("文件未找到: " + e.getMessage()); } }
public static void readFile(String fileName) throws IOException { BufferedReader reader = new BufferedReader(new FileReader(fileName)); String line = reader.readLine(); System.out.println(line); reader.close(); }}异常处理
编译时异常必须处理
对于编译时异常,必须在程序中处理,有两种方案,一种是捕获异常(使用 try-catch 语句),另一种是接着将异常抛到上级调用者(使用 throws 关键字)
运行时异常
概述
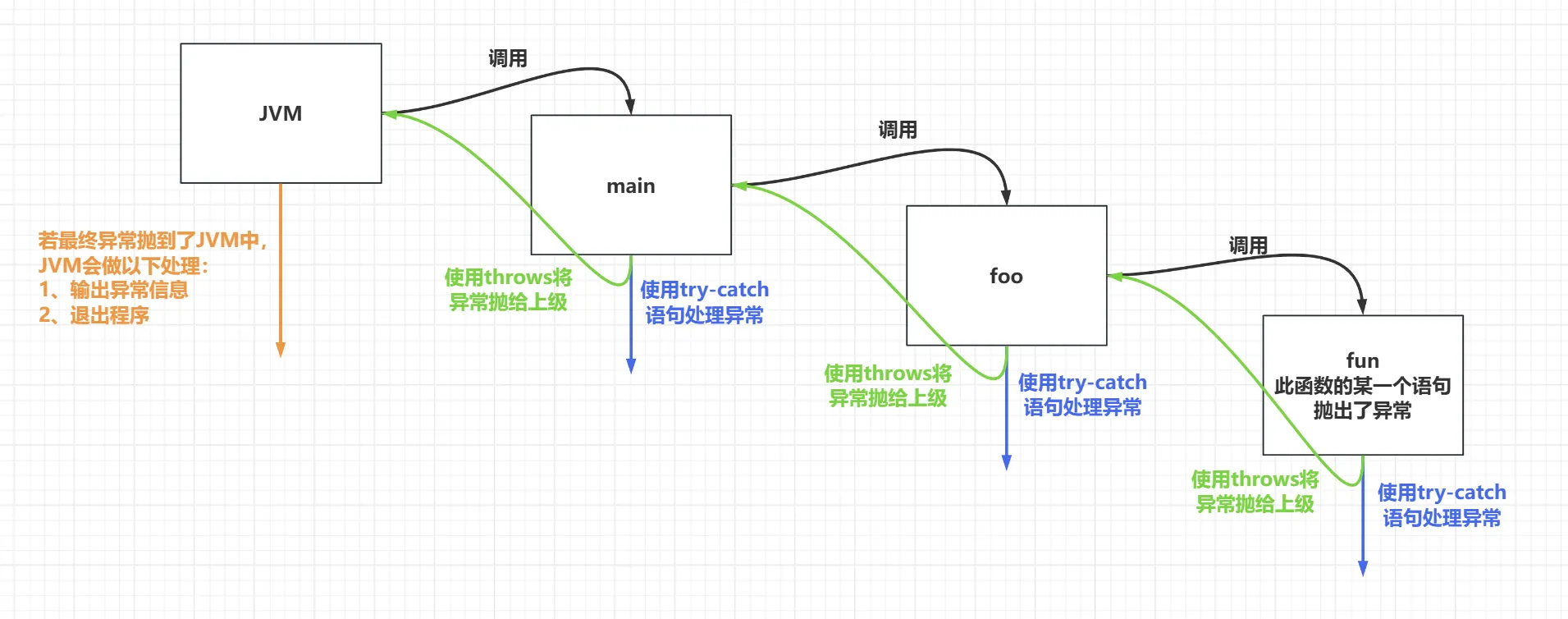
对于运行时异常,如果程序中没有使用 try-catch 处理,默认就是使用 throws 的方案处理。所以说运行时异常出现可以不进行处理,实际上个是因为它有默认处理方式,而且一般使用默认处理方式。
这里在 foo() 方法中会出现 ArithmeticException 异常,这是一个运行时异常,显然我们在 foo() 方法中没有对这个异常进行处理(使用 try-catch 语句),所以它默认是使用 throws 方案处理的,这个异常被抛到 main 方法中,然后又被 main 方法抛到 JVM 中,最终由 JVM 将异常信息打印出来,然后结束程序。
public class Example { public static void main(String[] args) { foo(); }
public static void foo() { int res = 1 / 0; }}子类重写父类方法抛出异常的限制
子类重写父类的方法时,如果父类的这个方法会抛出异常,则子类重写的方法可以不抛出异常(也就是使用 try-catch 处理这个异常),或者抛出父类异常的一样类型的异常,或者抛出父类异常的子类异常。
class SuperClass { public void foo() throws Exception { int res = 1 / 0; }}
class SubClass1 extends SuperClass { @Override public void foo() { // 不抛出异常 try{ int res = 1 / 0; } catch(ArithmeticException e) { System.out.println(e.getMessage()); } }}
class SubClass2 extends SuperClass { @Override public void foo() throws Exception { // 抛出父类异常同类型异常 int res = 1 / 0; }}
class SubClass3 extends SuperClass { @Override public void foo() throws ArithmeticException { // 抛出父类方法抛出异常的子类异常 int res = 1 / 0; }}API
String类
初识
初识string类
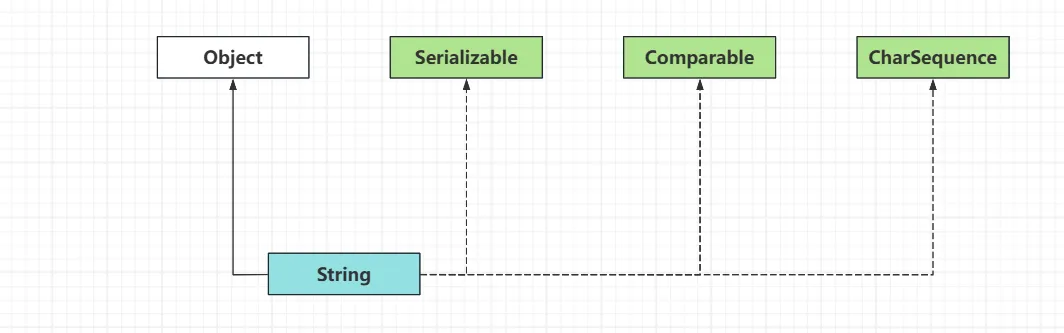
1.String 类是一个 final 类,不能被继承。
2.String 类直接继承 Object 类,同时,String 类实现了 Serializable、Comparable、CharSequence 接口。
接口的用途
实现 Serializable 接口用途:
Serializable 接口是一个标记接口,表示实现该接口的类可以被序列化。序列化是将对象的状态转换为字节流的过程,以便于存储或传输。
对于 String 类来说,实现 Serializable 接口使得字符串对象可以被安全地保存到文件中,或通过网络传输。将字符串对象序列化后存储到文件中或者通过网络发送时,可以方便地恢复原始的字符串对象。
实现 Comparable 接口用途:
Comparable 接口定义了一个比较两个对象的顺序的标准。
实现这个接口允许字符串对象按照字典顺序进行比较,这在排序和搜索时非常有用。
使用 Collections.sort() 方法对字符串列表进行排序时,String 类中的 compareTo(String anotherString) 方法将被调用,以确定字符串的自然顺序。
实现 CharSequence 接口用途:
CharSequence 接口允许 String 类提供对字符序列的访问。
这个接口定义了一组可以用于处理字符序列的方法,如 length()、charAt(int index)、subSequence(int start, int end) 等。
实现这个接口使得String类能够与其他处理字符序列的类(如 StringBuilder、StringBuffer 等)兼容。可以将 String 对象直接传递给需要 CharSequence 类型参数的方法,比如 StringBuilder 的构造函数。
构造器
string()
创建一个空字符串对象。
String str = new String();String(String original)
通过复制指定字符串的内容来创建一个新的字符串对象
String str = new String("Hello");String(char[] value)
通过字符数组创建字符串对象
char[] chars = {'H', 'e', 'l', 'l', 'o'};String str = new String(chars);String(byte[] bytes, int offset, int length)
byte[] bytes = {72, 101, 108, 108, 111, 32, 87, 111, 114, 108, 100};String str = new String(bytes, 0, 5); // "Hello"字符串储存
String 对象的内容是存储在一个名为 value 的字符数组中,而且这个数组是使用 final 修饰的,意味着一旦被初始化,它的引用不能被改变(只是引用不能修改,value 的每一个元素是可以修改的)。这个设计决定了 String 对象的不可变性,以及其在内存中的表现。
private final char value[];当创建一个 String 对象时,JVM 会为其分配内存,并在 value 数组中存储字符。value 数组会根据字符串的字符数动态大小化。字符串的每个字符会被存储为 char 类型,Java 使用 UTF-16 编码来表示字符,因此每个字符占用两个字节。
不可变性
不可变性认识
由上面的 String 对象的内容是被存储在一个 final 字符数组 value 中的,我们可知,String 对象是不可变的(immutable)。
这意味着一旦创建了一个 String 对象,它的值就不能被改变。如果你对字符串进行任何修改操作,比如拼接、替换等,实际上会生成一个新的 String 对象。
上面说到 value 被 final 修饰只是 value 的引用不能修改,而 value 的每一个元素值可以修改。如果你想要对 String 对象的某个字母进行修改,可以使用 replace 方法,但是这个方法实际上还是会返回一个新的对象:
其实不直接修改源字符串的 value 的某个元素还有一个原因,因为 value 可能指向字符串常量池的某个字符串常量,字符串常量是没法被修改的。
String original = "Hello";String modified = original.replace('H', 'J');// original 仍为 "Hello"// modified 为 "Jello"字符串常量
常量及池
1.字符串常量是指在程序中直接使用的固定字符串值。
String str = "Hello, World!";2、字符串常量池
字符串常量池(String Constant Pool)是用于存放字符串常量的特殊内存区域。这个池的主要作用是避免重复创建相同内容的字符串对象,从而节省内存。
public class Example { public static void main(String[] args) { String str1 = "Hello"; String str2 = "Hello";
System.out.println(str1 == str2); }}//ture str1 和 str2 指向的是同一个对象。字符串创建方式
只要使用了字符串常量,JVM 会先查找常量池中是否有相同的字符串常量,如果有,则什么也不做,如果没有的话,这个字符串常量会放到常量池。
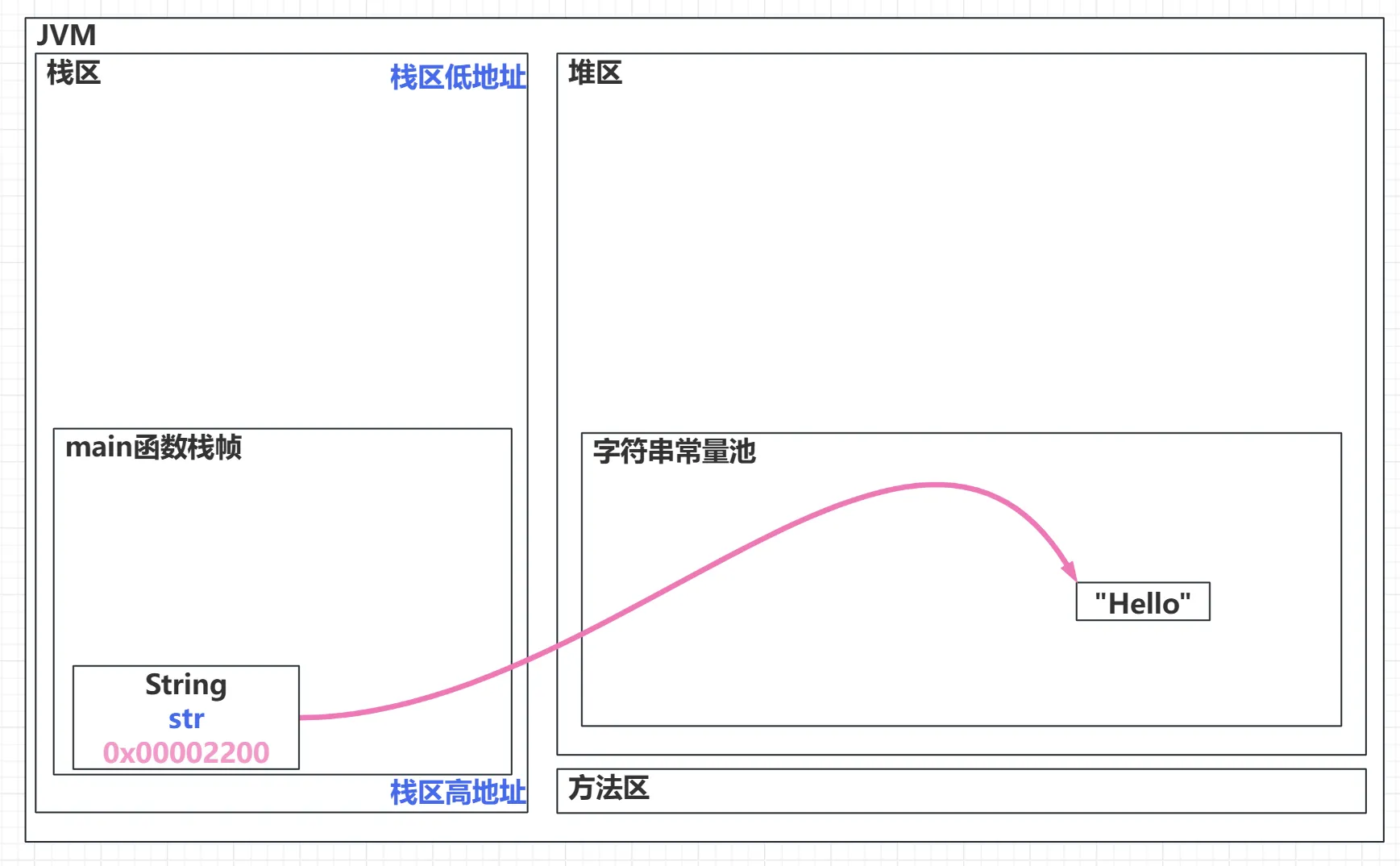
直接使用字符串常量赋值
认识
如果常量池没有相同的字符串常量的话,这个字符串常量会被放到常量池中,然后 String 引用变量会指向这个字符串常量。如果常量池中有相同的字符串常量,则 String 引用变量直接指向这个相同的字符串常量。
使用字符串常量加构造器创建
String str = new String("Hello");认识
JVM 会先在常量池中找是否有 “Hello” 这个字符串常量
如果有的话,在堆区创建一个 String 对象,然后这个对象的 value 字段指向常量池的 “Hello” 字符串常量。 如果常量池没有 “Hello” 这个字符串常量的话,则会在常量池中创建一个 “Hello” 字符串常量,然后在堆区创建一个 String 对象,然后这个对象的 value 字段指向常量池的 “Hello” 字符串常量。 这里为什么要有找这个字符串常量的动作呢,因为这里使用构造器创建时使用了字符串常量,我们上面提到过使用字符串常量就会导致这一系列动作。
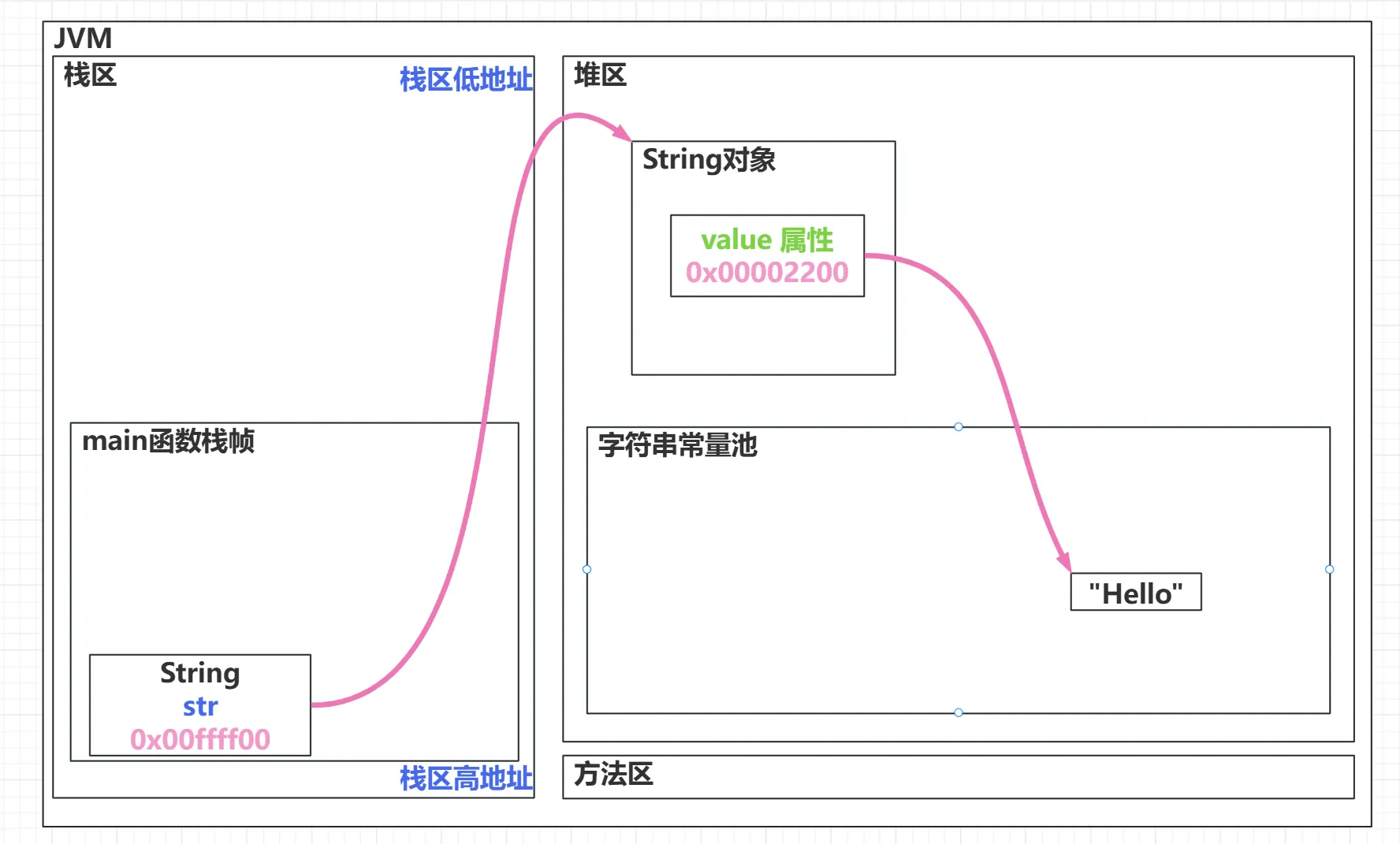
String str1 = "Hello"; String str2 = new String("Hello");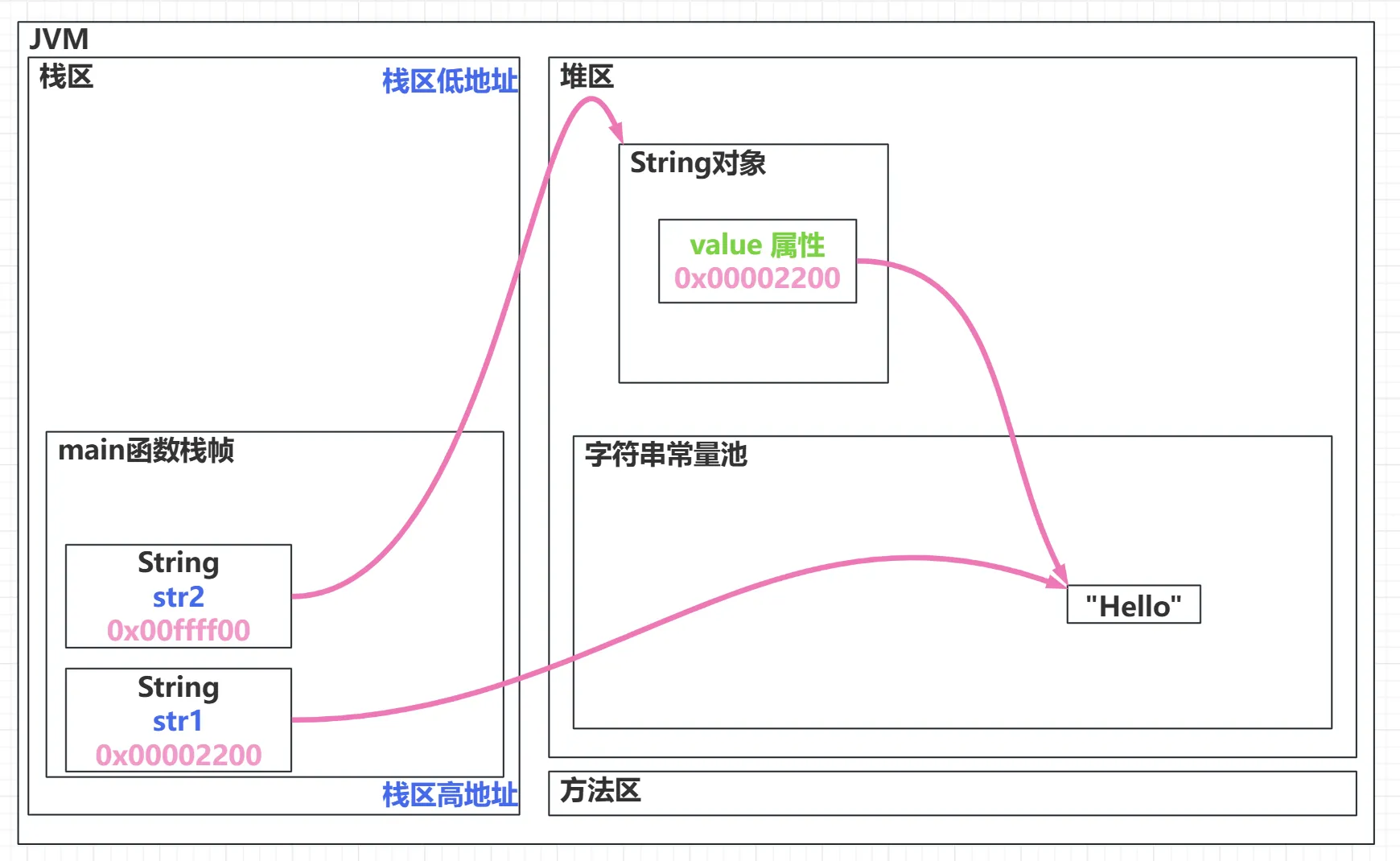
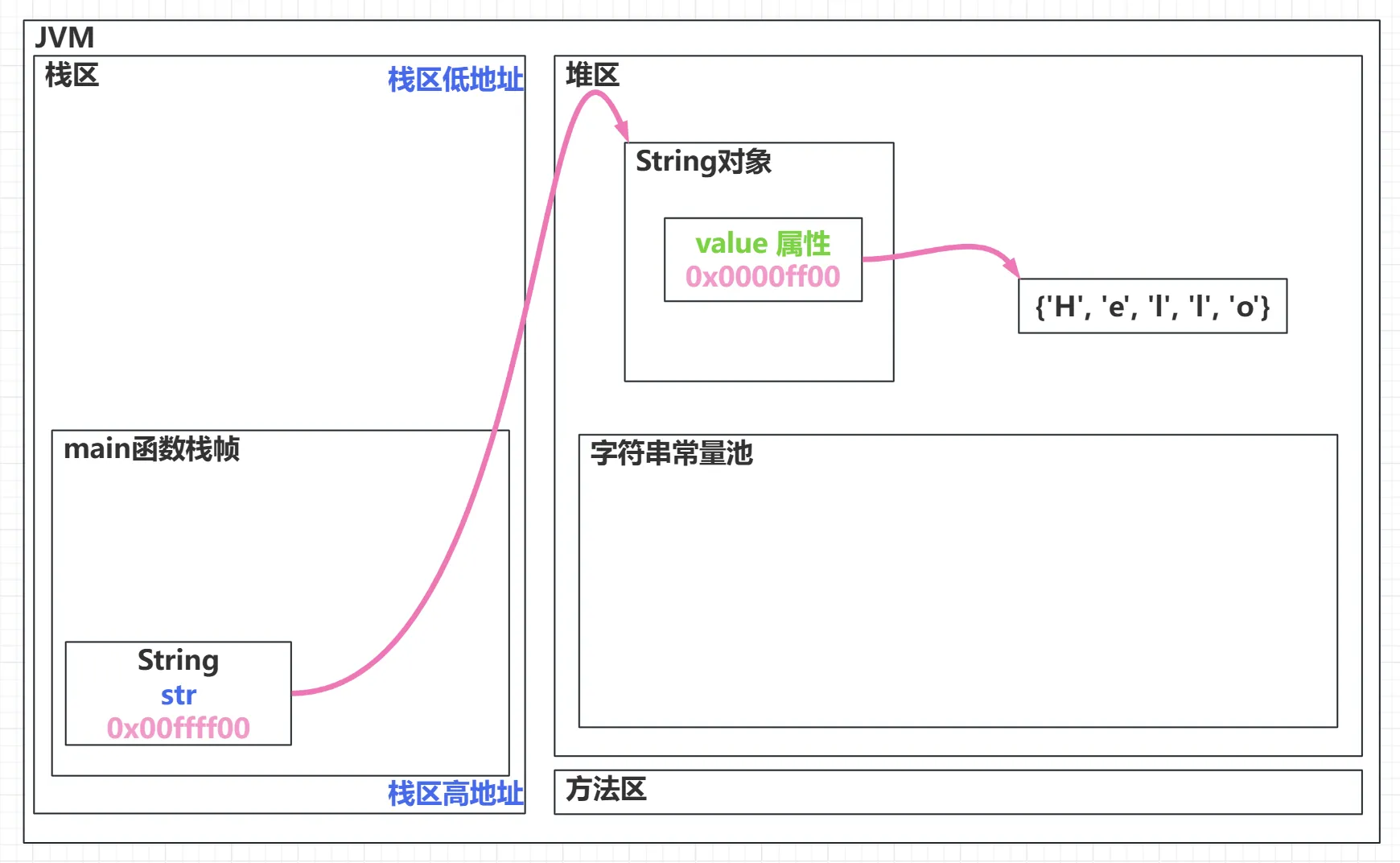
不使用或间接使用字符串常量创建
char[] chars = {'H', 'e', 'l', 'l', 'o'}; String str = new String(chars);这种方式会直接在堆区中创建 String 对象,然后 String 对象的 value 数组是从以上代码中的 chars 数组中复制得到的。
String str1 = new String("Hello"); String str2 = new String("World"); String str = str1 + str2;//方式二 堆对象// StringBuilder s = new StringBuilder; // s.append(str1); // s.append(str2); // str = s.toString();最后 toString 方法会创建一个新的 String 对象,而且常量池中没有与这个 String 对象内容一样的 字符串常量。intren方法
原理
当调用 intern() 方法时,JVM 会查看字符串常量池中是否有与当前字符串内容一样的字符串常量:
如果存在,则直接返回这个字符串常量的引用。 如果不存在,则将当前的 String 对象的引用放到常量池中,然后返回这个引用(这里只是将 当前的 String 对象的引用放到了常量池中,没有创建新的对象)。
JDK7 时将字符串常量从方法区移动到了堆区中。
public class Example { public static void main(String[] args) { String str = new String("Hello"); // 这里使用了字符串常量"Hello",所以它会被放到常量池
System.out.println(str == str.intern()); // false // 由于字符串常量池中有"Hello"常量,所以这里str.intern()返回的 // 是常量池中的"Hello"常量的引用,而str指向的是堆区的字符串对象, // 所以这里的结果是false }}public class Example { public static void main(String[] args) { String str1 = new String("Hello"); String str2 = new String("World");
String str = str1 + str2; // 这里是上面字符串创建方式提到的第三种创建方式 // 间接使用构造器创建,所以这里的str指向的是一个堆区的 // 字符串对象,而且常量池中没有与str内容一样的字符串常量
System.out.println(str == str.intern()); // true // 这里由于str指向的是一个新的在堆区的String对象,内容为"HelloWorld" // 而在常量池中没有与"HelloWorld"内容一样的字符串常量,所以,str的引用会被放入到常量池中,然后被返回,所以这里str.intern()返回的还是str,所以 // 这里会输出true }}public class Example { public static void main(String[] args) { String a = "123"; // a指向常量池的"123" String b = new String("123"); // b指向堆区的String对象, // String对象的value指向常量池的"123"
System.out.println(a.equals(b)); // true System.out.println(a == b); // false System.out.println(a == b.intern()); // true // 由于常量池中已经有了"123"常量,所以返回的是这个常量的引用, // 而a的引用就是这个常量的引用,所以这里结果为true System.out.println(b == b.intern()); // false // 这里b.intern()返回的是常量池中的"123"常量,对于b指向的则是堆区中的 // 对象,所以这里是结果false }}String常用方法
String常用方法
equals(Object obj): 比较两个字符串的内容是否相同,返回布尔值。
equalsIgnoreCase(String anotherString): 比较两个字符串的内容是否相同,忽略大小写,返回布尔值。
length(): 返回字符串的长度,即字符的数量。
indexOf(String str): 返回指定子字符串在字符串中首次出现的位置,如果未找到则返回-1。
lastIndexOf(String str): 返回指定子字符串在字符串中最后一次出现的位置,如果未找到则返回-1。
substring(int beginIndex): 从指定的开始索引返回一个子字符串。
substring(int beginIndex, int endIndex): 返回从指定的开始索引到结束索引之间的子字符串(不包括结束索引)。
trim(): 返回去除字符串前后空格的新字符串。
charAt(int index): 返回指定索引处的字符。
toUpperCase(): 返回一个新的字符串,将原字符串中的所有字符转换为大写。
toLowerCase(): 返回一个新的字符串,将原字符串中的所有字符转换为小写。
concat(String str): 将指定字符串连接到原字符串的末尾,返回新的字符串。
compareTo(String anotherString): 按字典顺序比较两个字符串,返回一个整数,表示它们的相对顺序。
toCharArray(): 将字符串转换为一个字符数组。
format(String format, Object… args): 使用指定的格式字符串和参数生成格式化的字符串
八大包装类
简要介绍
初识
包装类是用于将基本数据类型(如 int、char、boolean 等)包装成对象的类。每种基本数据类型都有对应的包装类,这些包装类提供了一种面向对象的方式来处理基本数据类型,允许它们被用于需要对象的场景,如集合框架、泛型等
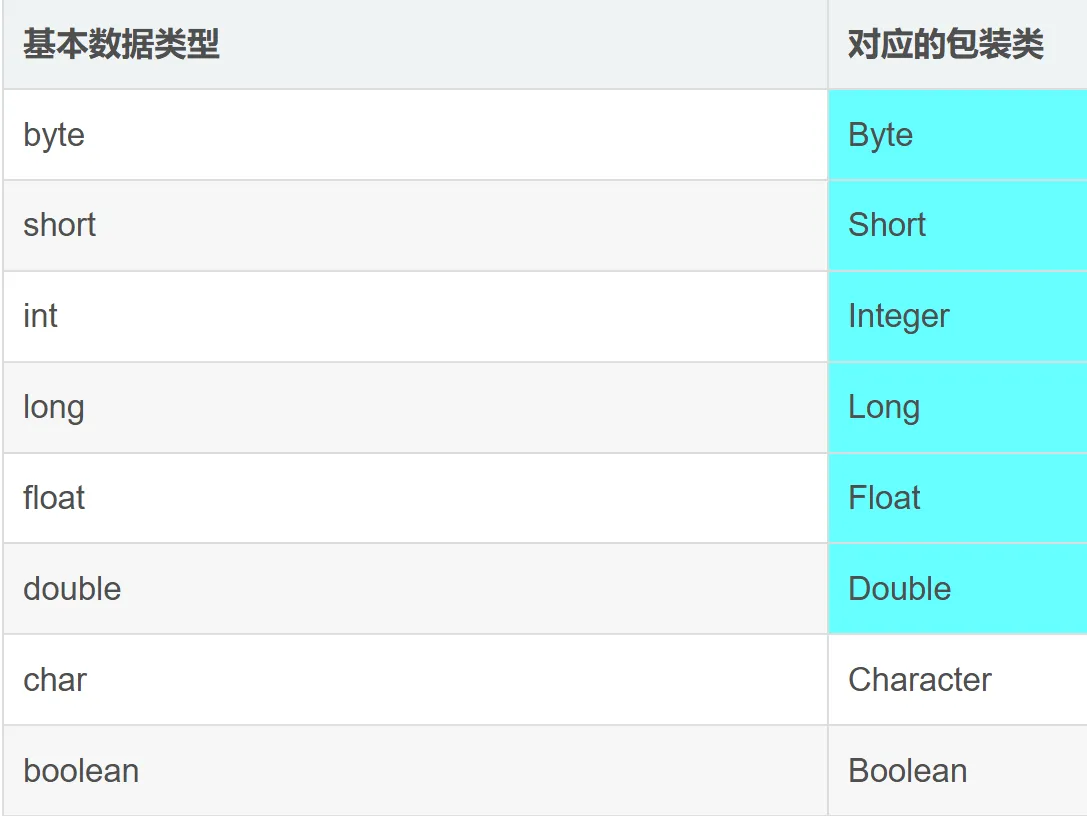
包装类的特点及用途
认识
包装类特点 封装性:所有的包装类都是 final 类,这意味着它们不能被继承。这种设计确保了包装类的行为和特性的一致性,从而避免了子类可能引入的不确定性。
不可变性:包装类的实例一旦被创建后,其中保存的基本数据类型数据就不能再被改变。这种不可变性使得包装类在多线程环境中更加安全,避免了因数据被意外修改而导致的错误。
提供方法:包装类封装了许多实用的方法,提供了丰富的功能。例如,它们支持数据类型转换、判断字符串的大小写、以及获取最大值和最小值等。
继承关系:除了 Character 和 Boolean 之外,其他所有的包装类都继承自 Number 类。这种继承关系使得这些包装类能够共享一些通用的功能和特性,例如数字的比较和转换,这为在不同数值类型之间的操作提供了一致的接口。
包装类的用途
对象操作:在Java中,许多集合类和框架方法需要对象作为参数,而不是基本数据类型。为了满足这一需求,包装类提供了将基本数据类型转换为对象的机制。通过使用包装类,我们可以轻松地在这些方法中传递基本数据类型。
Null值处理:基本数据类型无法为null,而包装类则可以。这一特性在某些情况下非常有用,例如在方法参数中,需要表示可选值或缺省值时。通过使用包装类,我们能够更灵活地处理这些场景,确保代码的健壮性和可读性。这种设计使得我们在处理数据时,可以更方便地进行null值检查,并在需要时安全地进行区分,从而提高了代码的灵活性。
手动装箱和拆箱
装箱(Boxing)是将基本数据类型转换为相应的包装类的过程。拆箱(Unboxing)是将包装类转换为基本数据类型的过程。
手动装箱就是使用一个值创建一个 Integer 对象
int num = 50000;
Integer boxedInt1 = new Integer(num); // 手动装箱方式一
Integer boxedInt2 = Integer.valueOf(num); // 手动装箱方式二手动拆箱就是使用 Integer 类型对象的 intValue() 方法来获取这个对象的 int 值
Integer boxedInt = new Integer(5);int num = boxedInt.intValue(); // 手动拆箱自动装拆箱
int num = 50000;Integer boxedInt = num; // 自动装箱Integer boxedInt = new Integer(50000);int num = boxedInt; // 自动拆箱底层
自动装箱的底层实现 自动装箱是通过调用包装类的valueOf()方法来实现的。
我们可以通过调试来验证这一结论,在要发生自动装箱的地方打上断点,然后直接跳到这个断点处,然后强制进入(force step into),就会进入到 valueOf() 方法中。
2)自动拆箱的底层实现 自动拆箱是通过调用包装类对象的xxxValue()方法来实现的。
我们可以通过调试来验证这一结论,在要发生自动拆箱的地方打上断点,然后直接跳到这个断点处,然后强制进入(force step into),就会进入到 xxxValue() 方法中。
包装类的缓存机制
初步认识
Java中的包装类缓存机制是为了优化性能和节省内存而设计的。
它为整型(Byte、Short、Integer、Long)、字符型(Character)和布尔型(Boolean)的包装类提供了缓存,确保在这些类型的小范围值之间可以复用对象。而对于浮点数类型的包装类(Float、Double),则没有这种缓存机制,意味着每次都需要创建新的对象。
这样一来,Java在处理常用值时更加高效,但在浮点数处理上则相对简单直接。
缓存范围
对于 Integer 类,Java会缓存范围在 -128 到 127 之间的所有整数。
对于 Byte、Short 和 Character 类,缓存的范围也是类似的。具体范围如下:
Byte:-128 到 127 Short:-128 到 127 Character:0 到 127(即所有的ASCII字符) Boolean:只有 true 和 false 两个值会被缓存
触发缓存机制
只有调用 valueOf() 方法时,如果要创建的值已经被缓存,则会触发缓存机制。
我们可以查看 Integer 类的 valueOf() 方法的源代码
public static Integer valueOf(int i) { if (i >= IntegerCache.low && i <= IntegerCache.high) return IntegerCache.cache[i + (-IntegerCache.low)]; return new Integer(i); }//如果要创建的 Integer 对象的值在预定范围内,则返回缓存的对象,如果不在范围内,则直接新创建一个对象。测试缓存机制
我们可以通过使用 valueOf() 方法创建两个值一样且值在范围内的对象,然后比较它们的引用是否相等,如果相等,则能证明缓存机制的存在。
public class Example { public static void main(String[] args) { Integer i1 = Integer.valueOf(1); Integer i2 = Integer.valueOf(1);
System.out.println(i1 == i2); }}包装类方法
基本转换方法
1.parseInt(String s), parseDouble(String s), parseBoolean(String s) 等:将字符串转换为相应的基本类型。
2.valueOf(String s): 返回对应类型的包装类实例,例如 Integer.valueOf(“123”) 返回一个 Integer 对象。
其他方法
初识
1**.获取基本类型值**
intValue(), doubleValue(), charValue(), booleanValue() 等: 返回包装类中封装的基本类型值。
2.比较方法
compareTo(T another): 用于比较两个包装类对象的大小。
equals(Object obj): 判断两个对象是否相等。
Integer.compare(x, y) 方法比较两个 Integer 对象的值。
3.类型检测
isNaN(), isInfinite(): 用于 Double 和 Float 以检测是否为非数字或无穷大。
**isLetter(char ch):**检查指定的字符是否为字母(包括大写和小写字母)。
**isDigit(char ch)**检查指定的字符是否为数字。
**isWhitespace(char ch):**检查指定的字符是否为白空格字符(如空格、制表符等)
包装类与字符串相互转换
Integer i = 10000;
// 方式一 String str1 = i + "";
// 方式二 String str2 = i.toString();
// 方式三 String str3 = String.valueOf(i);//对于方法三,实际上内部也是调用 toString() 方法的。 String str = "10000";
// 方式一 Integer i1 = Integer.parseInt(str);
// 方式二 Integer i2 = Integer.valueOf(str);
// 方式三 Integer i3 = new Integer(str);//这里看似通过字符串创建 Integer 类对象有三种方法,实际上就一种方法,对于方法二和方法三内部实际上都是调用 parseInt() 方法来将字符串转换为整型的。Math类
常用方法
初识Math类
Math 类是一个工具类,提供了一系列用于数学运算的方法。该类中的方法都是静态的,因此可以直接通过类名调用,而不需要创建 Math 类的实例。Math 类主要用于基本的数学计算,如三角函数、对数、平方根等。
Math 类 位于 java.lang 包中,因此无需导入即可使用,它是一个 final 类,这意味着它不能被继承。
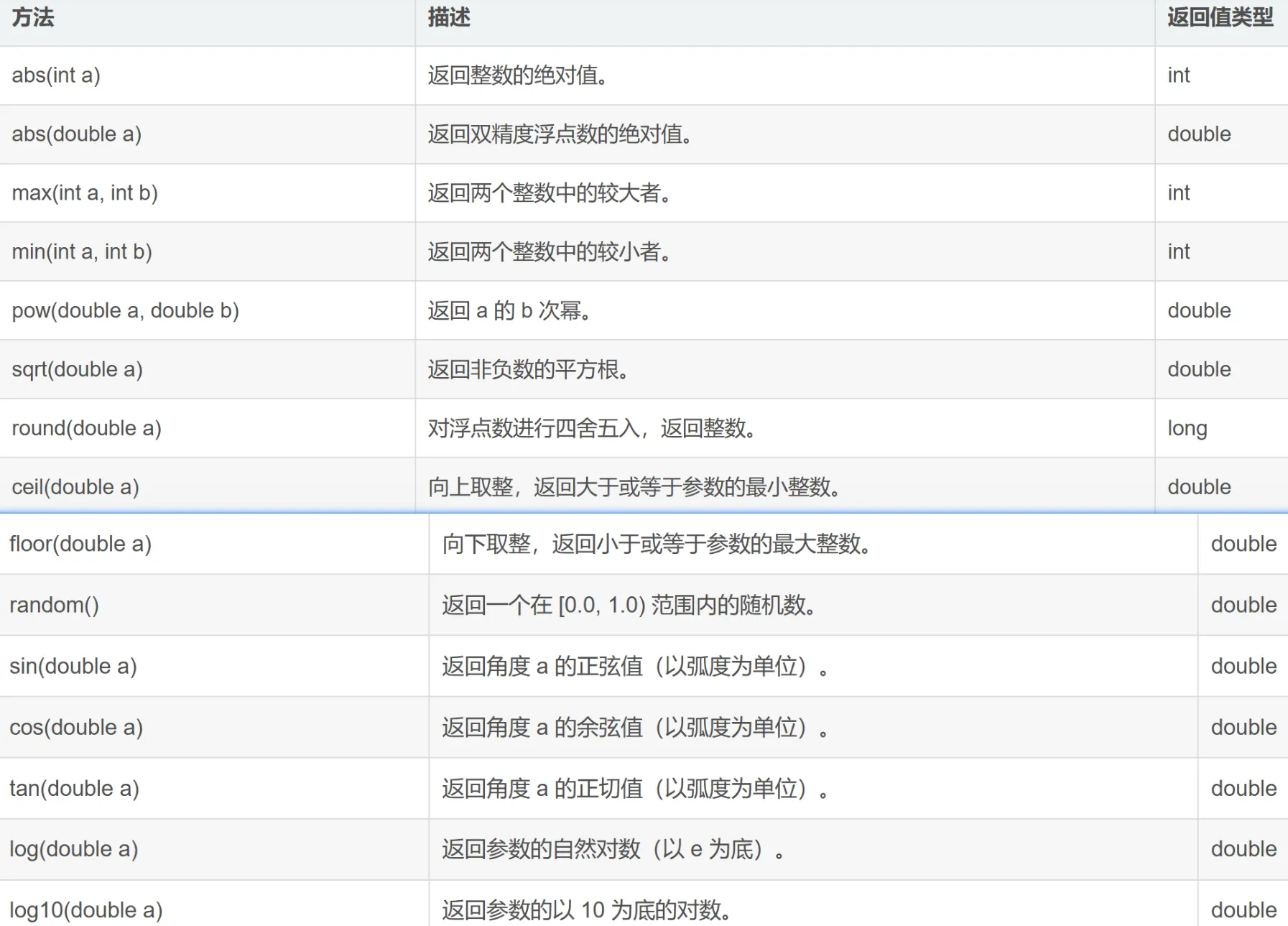
random方法使用公式
//生成特定范围的随机浮点数double min = 5.0; // 最小值double max = 10.0; // 最大值double randomValue = min + (Math.random() * (max - min));//生成特定范围的随机整数int min = 5; // 最小值int max = 10; // 最大值int randomInt = min + (int)(Math.random() * (max - min + 1));//生成随机布尔值boolean randomBoolean = Math.random() < 0.5;//生成随机字符(例如:小写字母char randomChar = (char)('a' + Math.random() * 26);//生成指定长度的随机字符串StringBuilder randomString = new StringBuilder();int length = 10; // 指定字符串长度for (int i = 0; i < length; i++) { char randomChar = (char)('a' + Math.random() * 26); // 生成小写字母 randomString.append(randomChar);}System类
常用方法
1、arraycopy
用于快速复制数组 。这比使用循环进行复制更高效
import java.util.Arrays;
public class Example { public static void main(String[] args) { String[] arr1 = {"Hello", "World", "HelloWorld"};
String[] arr2 = new String[3];
System.arraycopy(arr1, 0, arr2, 0, arr1.length);
System.out.println(Arrays.toString(arr2)); }}public class Example { public static void main(String[] args) { System.out.println("Hello");
System.exit(1);
System.out.println("World"); // 这一句将不会被输出 }}public class Example { public static void main(String[] args) { String s = new String();
long startTime = System.currentTimeMillis();
for(int i = 0; i < 10000; i++) { s += "Hello"; }
long endTime = System.currentTimeMillis(); System.out.println("Execution time: " + (endTime - startTime) + " ms"); }}StringBuilder和StingBuffer类
StringBuffer
Arrays类
简要介绍
Arrays 类是 Java 语言中用于操作数组的一个工具类,提供了多种静态方法来处理数组,包括排序、搜索、填充、比较等操作。这个类位于 java.util 包中。
Arrays类的构造方法被设置为私有(private),因此无法创建 Arrays 对象。Arrays 类的所有公有方法都是静态的,可以直接通过类名调用
Arrays.toString()方法
使用实例
import java.util.Arrays;
public class Example { public static void main(String[] args) { int[] arr = {1, 2, 3, 4, 5, 6}; System.out.println(Arrays.toString(arr)); }}源码分析
public static String toString(int[] a) { if (a == null) // 判断 a 是否为空引用,如果为空引用,则返回 "null" 字符串 return "null"; int iMax = a.length - 1; if (iMax == -1) // 判断数组内容是否为空,如果内容为空,则返回 "[]" 字符串 return "[]";
StringBuilder b = new StringBuilder(); b.append('['); for (int i = 0; ; i++) { b.append(a[i]); // 依次将数组的元素追加到字符串中 if (i == iMax) // 判断是否为最后一个元素,如果是最后一个元素,则返回最终的字符串 return b.append(']').toString(); b.append(", "); } }Arrays.copyof()方法
import java.util.Arrays;
public class Example { public static void main(String[] args) { // 原始数组 int[] originalArray = {1, 2, 3, 4, 5};
// 复制数组,指定新数组的长度 // 新数组长度小于原数组长度 int[] newArray1 = Arrays.copyOf(originalArray, 3); System.out.println("新数组1: " + Arrays.toString(newArray1)); // 输出: [1, 2, 3]
// 新数组长度大于原数组长度 int[] newArray2 = Arrays.copyOf(originalArray, 8); System.out.println("新数组2: " + Arrays.toString(newArray2)); // 输出: [1, 2, 3, 4, 5, 0, 0, 0]
// 新数组长度等于原数组长度 int[] newArray3 = Arrays.copyOf(originalArray, originalArray.length); System.out.println("新数组3: " + Arrays.toString(newArray3)); // 输出: [1, 2, 3, 4, 5] }}//第一个参数是源数组,第二个参数是从源数组中复制多少个元素到新数组中,如果第二个参数大于了源数组的大小,则新数组中大于源数组大小的部分的元素都是类型默认值。Arrays.sort()方法
import java.util.Arrays;
public class Example { public static void main(String[] args) { int[] arr = {11, 33, 99, 22, 88, 44, 55, 66, 77}; Arrays.sort(arr); System.out.println(Arrays.toString(arr)); }}使用comparator接口
import java.util.Arrays;import java.util.Comparator;
public class Example { public static void main(String[] args) { Integer[] arr = {11, 33, 99, 22, 88, 44, 55, 66, 77}; // 这里要使用 Integer 包装类
Arrays.sort(arr, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2 - o1; } }); System.out.println(Arrays.toString(arr)); }}这里的数组不能使用基本数据类型,因为这里的 sort() 方法的声明是这样的
public static <T> void sort(T[] a, Comparator<? super T> c);这里的 sort 是一个泛型方法,泛型参数只能接受类类型,所以这里需要使用包装类型数组作为第一个参数,对于第二个参数,我们传入的是
new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { return o2 - o1; } }代码解释
这显然是一个匿名内部类,它实现了 Comparator 接口,同时重写了这个接口的 compare() 方法,这个方法是关键,这里返回值是 o2 - o1,这就代表了,如果 o1 如果大于 o2 的话,则返回负值,对于 sort() 方法内部某个地方就是调用的 compare() 方法来比较两个参数的大小。
如果是升序的话,o1 大于 o2 应当返回的是正值,这里返回了负值,所以就是将顺序设置为反的,所以最终可以得到降序的数组。
使用的相关算法
简要分析
基本类型数组(如 int[], char[] 等):
对于基本数据类型数组,Arrays.sort() 方法使用了一种名为 Dual-Pivot Quicksort 的排序算法。这是一种改进的快速排序算法,由 Vladimir Yaroslavskiy 提出。它在平均情况下具有 O(n log n) 的时间复杂度,并且在实践中通常表现良好。
对象类型数组(如 Integer[], String[] 等):
对于对象数组,Arrays.sort() 方法则使用 Timsort 算法。这是一种混合排序算法,结合了归并排序和插入排序的优点。Timsort 是为了优化对部分有序数据的排序而设计的,具有 O(n log n) 的时间复杂度,并且在实际应用中表现出色。
Arrays.binarySearch()方法
import java.util.Arrays;
public class Example { public static void main(String[] args) { int[] arr = {11, 22, 33, 44, 55, 66, 77, 88, 99};
// Arrays.sort(arr) // 在调用 binarySearch 前需要对数组先进行排序 // 这里为了方便比对结果,数组已经是有序的 int index = Arrays.binarySearch(arr, 99);
System.out.println("index of 99: " + index); }}Arrays.fill()方法
用指定的值填充数组,如果想要将一个数组的所有元素都是设置为某个值的话,可以使用这个方法。
import java.util.Arrays;
public class Example { public static void main(String[] args) { int[] arr = new int[10]; Arrays.fill(arr, 2333);
System.out.println(Arrays.toString(arr)); }}Arrays.equals方法
Arrays.equals() 方法用于比较两个一维数组是否相等。
import java.util.Arrays;
public class Example { public static void main(String[] args) { int[] array1 = {1, 2, 3}; int[] array2 = {1, 2, 3}; int[] array3 = {1, 2, 4};
// 比较相同的数组 boolean isEqual1 = Arrays.equals(array1, array2); System.out.println("array1 和 array2 相等? " + isEqual1); // 输出: true
// 比较不同的数组 boolean isEqual2 = Arrays.equals(array1, array3); System.out.println("array1 和 array3 相等? " + isEqual2); // 输出: false }}Arrays.deepequals()方法
Arrays.deepEquals() 方法用于比较两个多维数组是否相等。它会递归地比较数组的每个元素。如果使用 Arrays.equals() 方法的话,则只会比较每一个低一维数组的引用是否相等。
import java.util.Arrays;
public class Example { public static void main(String[] args) { int[][] array1 = {{1, 2, 3}, {4, 5, 6}}; int[][] array2 = {{1, 2, 3}, {4, 5, 6}}; int[][] array3 = {{1, 2, 3}, {4, 5, 7}};
// 比较相同的二维数组 boolean isEqual1 = Arrays.deepEquals(array1, array2); System.out.println("array1 和 array2 相等? " + isEqual1); // 输出: true
// 比较不同的二维数组 boolean isEqual2 = Arrays.deepEquals(array1, array3); System.out.println("array1 和 array3 相等? " + isEqual2); // 输出: false }}Arrays.asLIst()方法
Arrays.asList() 方法是 Java 中的一个静态方法,属于 java.util.Arrays 类。它可以将指定的数组转换为一个固定大小的列表(List)。这个方法返回一个 List 的视图,修改该列表会影响原始数组,反之亦然。
import java.util.Arrays;import java.util.List;
public class Example { public static void main(String[] args) { Integer[] numbersArray = {1, 2, 3, 4, 5};
// 转换为列表 List<Integer> numbersList = Arrays.asList(numbersArray);
// 修改列表中的元素 numbersList.set(0, 10);
// 打印修改后的列表和数组 System.out.println("修改后的列表: " + numbersList); // 输出: 修改后的列表: [10, 2, 3, 4, 5] System.out.println("修改后的数组: " + Arrays.toString(numbersArray)); // 输出: 修改后的数组: [10, 2, 3, 4, 5] }}不能添加元素
import java.util.Arrays;import java.util.List;
public class Example { public static void main(String[] args) { String[] colorsArray = {"Red", "Green", "Blue"};
// 转换为列表 List<String> colorsList = Arrays.asList(colorsArray);
// 尝试添加新元素(会抛出 UnsupportedOperationException) try { colorsList.add("Yellow"); } catch (UnsupportedOperationException e) { System.out.println("无法添加元素到列表: " + e.getMessage()); } }}//固定大小:返回的 List 的大小是固定的,因为原数组的大小是固定的。换句话说,您不能向该列表中添加或删除元素,因为这会导致列表的大小发生变化。当尝试调用 add() 或 remove() 方法来修改列表的大小时,会抛出 UnsupportedOperationException集合框架
简要引入
简要引入
集合框架(Java Collections Framework)是一个用于存储和操作数据的架构,它提供了一组接口和类,用于处理不同类型的数据集合。集合框架的设计旨在提高代码的可重用性和灵活性。集合框架主要是从两个根接口:Collection 和 Map发散出来的。
我们知道数组创建之后大小就是固定的了,如果想要扩容还需要新建数组,然后将之前的数据复制到新数组中。使用集合框架,则可以解决这一问题。
collection单列集合
单列结构:Collection 接口及其子接口(如 List、Set 和 Queue)主要用于存储单一类型的元素。每个集合只包含元素,不涉及键值对的概念。
1.List代表了有序元素插入顺序 = 遍历顺序可重复集合,可直接根据元素的索引来访问
2.Set代表无序不可重复集合,只能根据元素本身来访问
3.Queue是队列集合,用于按特定顺序处理元素

map双列集合
双列结构:Map 接口用于存储键值对(key-value pairs),其中每个键(key)都与一个值(value)相关联。每个键是唯一的,而值可以重复。常见实现包括:
HashMap:基于哈希表实现,允许快速查找,不保持元素的插入顺序。 TreeMap:基于红黑树实现,保持键的自然顺序或指定的顺序。 LinkedHashMap:保持元素的插入顺序
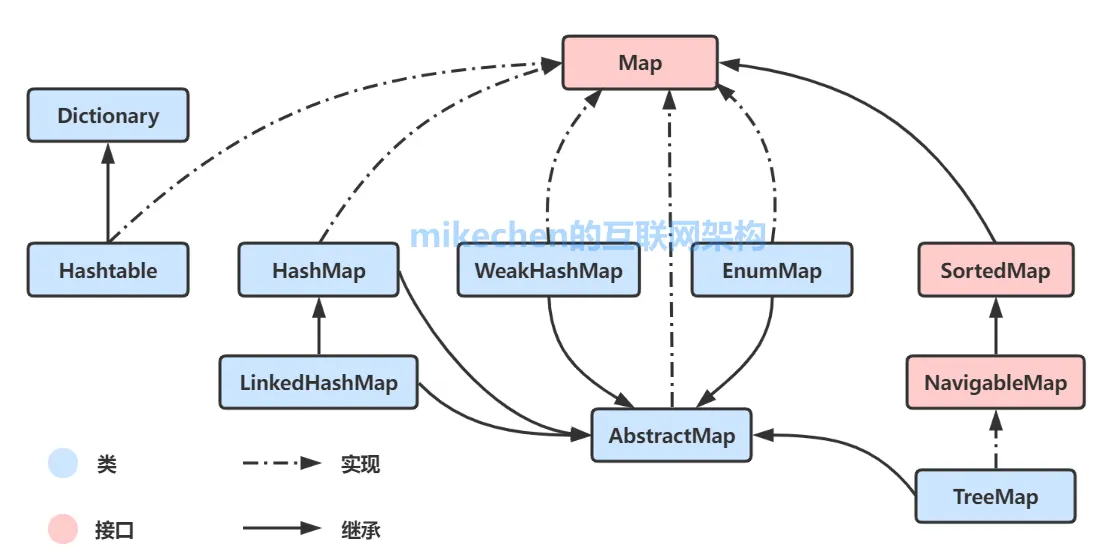
Collection接口
List接口
ArrayList实现类
初识ArrayList
List 接口的核心特点是 有序(元素插入顺序 = 遍历顺序)、可重复,支持通过索引操作元素,适合需要按位置访问、频繁查询的场景。
(1)ArrayList:数组实现的 “动态数组”(最常用) 底层原理:基于数组实现,默认初始容量为 10,当元素个数超过容量时,会扩容为原来的 1.5 倍(oldCapacity + (oldCapacity >> 1)),扩容时会复制原数组元素到新数组; 核心特点:查询快(数组支持索引随机访问,时间复杂度 O (1))、增删慢(需移动数组元素,时间复杂度 O (n)); 适用场景:频繁查询、少量增删的场景(如商品列表展示、数据查询结果存储)
import java.util.ArrayList;import java.util.List;
public class ArrayListDemo { public static void main(String[] args) { // 1. 创建ArrayList(存储字符串) List<String> list = new ArrayList<>();
// 2. 添加元素(有序、可重复) list.add("Java"); list.add("Python"); list.add("Java"); // 允许重复元素 System.out.println("添加后:" + list); // 输出:[Java, Python, Java]
// 3. 按索引访问元素 String element = list.get(1); System.out.println("索引1的元素:" + element); // 输出:Python
// 4. 按索引修改元素 list.set(2, "C++"); System.out.println("修改后:" + list); // 输出:[Java, Python, C++]
// 5. 按索引删除元素 list.remove(1); System.out.println("删除后:" + list); // 输出:[Java, C++]
// 6. 遍历元素(三种方式) // 方式1:普通for循环(适合需要索引的场景) for (int i = 0; i < list.size(); i++) { System.out.print(list.get(i) + " "); } System.out.println();
// 方式2:增强for循环(简洁) for (String s : list) { System.out.print(s + " "); } System.out.println();
// 方式3:迭代器(支持遍历中删除元素) java.util.Iterator<String> iterator = list.iterator(); while (iterator.hasNext()) { String s = iterator.next(); if (s.equals("Java")) { iterator.remove(); // 安全删除,不会触发ConcurrentModificationException } } System.out.println("迭代器删除后:" + list); // 输出:[C++] }}LinkedList实现类
初识LinkedList实现类
LinkedList:双向链表实现的 “链表集合” 底层原理:基于双向链表实现,每个元素(节点)包含前驱节点、后继节点的引用,无需连续内存空间; 核心特点:查询慢(需遍历链表,时间复杂度 O (n))、增删快(只需修改节点引用,时间复杂度 O (1)); 适用场景:频繁增删、少量查询的场景(如队列、栈、消息队列)
import java.util.LinkedList;import java.util.List;
public class LinkedListDemo { public static void main(String[] args) { List<Integer> list = new LinkedList<>();
// 添加元素 list.add(10); list.add(20); list.add(30); System.out.println("添加后:" + list); // 输出:[10, 20, 30]
// 在指定位置插入元素(增删效率高) list.add(1, 15); System.out.println("插入后:" + list); // 输出:[10, 15, 20, 30]
// 删除指定元素 list.remove(Integer.valueOf(20)); System.out.println("删除后:" + list); // 输出:[10, 15, 30]
// 链表特有的操作(作为队列/栈) LinkedList<Integer> linkedList = (LinkedList<Integer>) list; linkedList.addFirst(5); // 头部添加 linkedList.addLast(35); // 尾部添加 System.out.println("头部+尾部添加后:" + linkedList); // 输出:[5, 10, 15, 30, 35]
int first = linkedList.getFirst(); // 获取头部元素 int last = linkedList.getLast(); // 获取尾部元素 System.out.println("头部:" + first + ",尾部:" + last); // 输出:头部:5,尾部:35 }}
set接口
HashSet实现类
初识HashSet
Set 接口:无序、不可重复的 “集合”
Set 接口的核心特点是 无序(元素插入顺序≠遍历顺序)、不可重复(基于equals()和hashCode()判断),适合需要去重的场景。
HashSet:哈希表实现的去重集合(最常用) 底层原理:基于 HashMap 实现(HashSet 的元素作为 HashMap 的 key,value 为固定常量),利用哈希表保证元素唯一; 核心特点:无序、不可重复、查询和增删效率高(时间复杂度 O (1)); 去重规则:先通过hashCode()计算哈希值,若哈希值不同则元素不同;
不同的元素hash值可能相同
若哈希值相同,再通过equals()判断是否相同,两者都相同则视为重复元素
import java.util.HashSet;import java.util.Set;
public class HashSetDemo { public static void main(String[] args) { Set<String> set = new HashSet<>(); //接口多态编译左边实现右边
// 添加元素(不可重复) set.add("Apple"); set.add("Banana"); set.add("Apple"); // 重复元素,添加失败 System.out.println("添加后:" + set); // 输出:[Apple, Banana](无序)
// 删除元素 set.remove("Banana"); System.out.println("删除后:" + set); // 输出:[Apple]
// 判断元素是否存在 boolean contains = set.contains("Apple"); System.out.println("是否包含Apple:" + contains); // 输出:true
// 遍历元素(增强for/迭代器,无普通for循环,因为无序无索引) for (String s : set) { System.out.print(s + " "); // 输出:Apple }
// 去重场景示例:数组去重 String[] arr = {"Java", "Python", "Java", "C++"}; Set<String> uniqueSet = new HashSet<>(); for (String s : arr) { uniqueSet.add(s); } System.out.println("\n数组去重后:" + uniqueSet); // 输出:[Java, Python, C++] }}LinkedHashSet实现类
认识LinkedHashSet
LinkedHashSet:有序的去重集合
- 底层原理:基于 HashMap + 双向链表实现,链表记录元素插入顺序,哈希表保证元素唯一;
- 核心特点:有序(插入顺序 = 遍历顺序)、不可重复、效率略低于 HashSet;
- 适用场景:需要去重且保持插入顺序的场景(如用户浏览记录去重)。
TreeSet实现类
初识TreeSet
- 底层原理:基于红黑树实现,元素会按自然顺序(或自定义比较器)排序;
- 核心特点:有序(排序后顺序)、不可重复、查询和增删效率 O (logn);
- 适用场景:需要去重且排序的场景(如成绩排名、数据按关键字排序)
import java.util.TreeSet;
public class TreeSetDemo { public static void main(String[] args) { // 1. 自然排序(Integer按数值升序) TreeSet<Integer> numSet = new TreeSet<>(); numSet.add(30); numSet.add(10); numSet.add(20); System.out.println("自然排序:" + numSet); // 输出:[10, 20, 30]
// 2. 自定义排序(字符串按长度降序) TreeSet<String> strSet = new TreeSet<>((s1, s2) -> s2.length() - s1.length()); strSet.add("Apple"); strSet.add("Banana"); strSet.add("Pear"); System.out.println("自定义排序(长度降序):" + strSet); // 输出:[Banana, Apple, Pear] }}Queue接口
初识对列
Queue 接口:先进先出的 “队列” Queue 接口遵循 先进先出(FIFO) 原则,元素从队列尾部添加,从头部删除,适合任务排队、消息传递等场景。
核心方法 offer(E e):添加元素到队列尾部,失败返回 false(推荐使用,不抛出异常); poll():删除并返回队列头部元素,队列为空返回 null; peek():返回队列头部元素,不删除,队列为空返回 null; remove():删除并返回队列头部元素,队列为空抛出异常。
import java.util.LinkedList;import java.util.Queue;
public class QueueDemo { public static void main(String[] args) { Queue<String> queue = new LinkedList<>();
// 添加元素到队列 queue.offer("任务1"); queue.offer("任务2"); queue.offer("任务3"); System.out.println("队列初始化:" + queue); // 输出:[任务1, 任务2, 任务3]
// 获取头部元素(不删除) String head = queue.peek(); System.out.println("队列头部:" + head); // 输出:任务1
// 删除并返回头部元素 String task = queue.poll(); System.out.println("执行任务:" + task); // 输出:执行任务:任务1 System.out.println("执行后队列:" + queue); // 输出:[任务2, 任务3] }}Map接口
HashMap实现类
认识HashMap
Map 接口存储 键值对(key-value),key 唯一(不可重复),value 可重复,每个 key 对应一个 value,适合通过 key 快速查找 value 的场景(如用户信息存储、配置项管理)。
- HashMap:哈希表实现的键值对集合(最常用) 底层原理:JDK8 之前是 “数组 + 链表”,JDK8 之后是 “数组 + 链表 + 红黑树”;当链表长度超过阈值(8)且数组容量≥64 时,链表转为红黑树(提高查询效率);当链表长度≤6 时,红黑树转回链表(节省内存); 核心特点:无序、key 唯一、查询和增删效率高(O (1))、线程不安全; key 去重规则:同 HashSet,基于hashCode()和equals()判断。
import java.util.HashMap;import java.util.Map;import java.util.Set;
public class HashMapDemo { public static void main(String[] args) { // 1. 创建HashMap(存储用户ID-用户名) Map<Integer, String> userMap = new HashMap<>();
// 2. 添加键值对(key唯一,重复key会覆盖value) userMap.put(1001, "张三"); userMap.put(1002, "李四"); userMap.put(1001, "张三三"); // 重复key,覆盖value System.out.println("添加后:" + userMap); // 输出:{1001=张三三, 1002=李四}
// 3. 根据key获取value String username = userMap.get(1001); System.out.println("用户1001的名称:" + username); // 输出:张三三
// 4. 判断key是否存在 boolean hasKey = userMap.containsKey(1002); System.out.println("是否存在key=1002:" + hasKey); // 输出:true
// 5. 删除键值对 userMap.remove(1002); System.out.println("删除后:" + userMap); // 输出:{1001=张三三}
// 6. 遍历HashMap(三种方式) // 方式1:遍历key集合 Set<Integer> keySet = userMap.keySet(); for (Integer key : keySet) { System.out.println("key:" + key + ",value:" + userMap.get(key)); }
// 方式2:遍历entrySet(推荐,效率高,避免多次get) Set<Map.Entry<Integer, String>> entrySet = userMap.entrySet(); for (Map.Entry<Integer, String> entry : entrySet) { System.out.println("key:" + entry.getKey() + ",value:" + entry.getValue()); }
// 方式3:遍历value集合(无法获取key) for (String value : userMap.values()) { System.out.println("value:" + value); } }}LinkedMap实现类
认识LinkedMap
- 底层原理:基于 HashMap + 双向链表实现,链表记录键值对的插入顺序或访问顺序;
- 核心特点:有序(插入顺序或访问顺序)、key 唯一、效率略低于 HashMap;
- 适用场景:需要保持键值对顺序的场景(如缓存 LRU 策略、历史操作记录)
import java.util.LinkedHashMap;import java.util.Map;
public class LinkedHashMapDemo { public static void main(String[] args) { // 1. 按插入顺序排序(默认) Map<String, Integer> insertOrderMap = new LinkedHashMap<>(); insertOrderMap.put("Apple", 10); insertOrderMap.put("Banana", 20); insertOrderMap.put("Pear", 15); System.out.println("插入顺序:" + insertOrderMap); // 输出:{Apple=10, Banana=20, Pear=15}
// 2. 按访问顺序排序(LRU策略) Map<String, Integer> accessOrderMap = new LinkedHashMap<>(16, 0.75f, true); accessOrderMap.put("Apple", 10); accessOrderMap.put("Banana", 20); accessOrderMap.put("Pear", 15);
// 访问Banana和Apple accessOrderMap.get("Banana"); accessOrderMap.get("Apple"); System.out.println("访问顺序:" + accessOrderMap); // 输出:{Pear=15, Banana=20, Apple=10} }}TreeMap实现类
认识treeMap
- 底层原理:基于红黑树实现,key 按自然顺序或自定义比较器排序;
- 核心特点:有序(key 排序后顺序)、key 唯一、查询和增删效率 O (logn);
- 适用场景:需要按 key 排序的场景(如成绩排名表、字典序查询)
import java.util.TreeMap;
public class TreeMapDemo { public static void main(String[] args) { // 1. 自然排序(Integer按数值升序) TreeMap<Integer, String> numMap = new TreeMap<>(); numMap.put(3, "C"); numMap.put(1, "A"); numMap.put(2, "B"); System.out.println("自然排序:" + numMap); // 输出:{1=A, 2=B, 3=C}
// 2. 自定义排序(key按字符串长度降序) TreeMap<String, Integer> strMap = new TreeMap<>((s1, s2) -> s2.length() - s1.length()); strMap.put("Apple", 10); strMap.put("Banana", 20); strMap.put("Pear", 15); System.out.println("自定义排序:" + strMap); // 输出:{Banana=20, Apple=10, Pear=15} }}ConCurrentHashMap实现类
认识ConCurrentHashMap
ConcurrentHashMap:线程安全的高效并发集合 底层原理:JDK8 之前是 “分段锁”,JDK8 之后是 “CAS+ synchronized”,只锁定链表 / 红黑树的节点,不锁定整个数组,并发效率高; 核心特点:线程安全、高效并发、key 唯一、无序; 适用场景:多线程环境下的键值对存储(如分布式系统中的共享配置、缓存)。
import java.util.Map;import java.util.concurrent.ConcurrentHashMap;
public class ConcurrentHashMapDemo { public static void main(String[] args) throws InterruptedException { Map<Integer, Integer> map = new ConcurrentHashMap<>();
// 多线程并发添加元素 Runnable task = () -> { for (int i = 0; i < 1000; i++) { map.put(i, i); } };
Thread t1 = new Thread(task); Thread t2 = new Thread(task); t1.start(); t2.start(); t1.join(); t2.join();
System.out.println("最终元素个数:" + map.size()); // 输出:1000(无并发问题) }}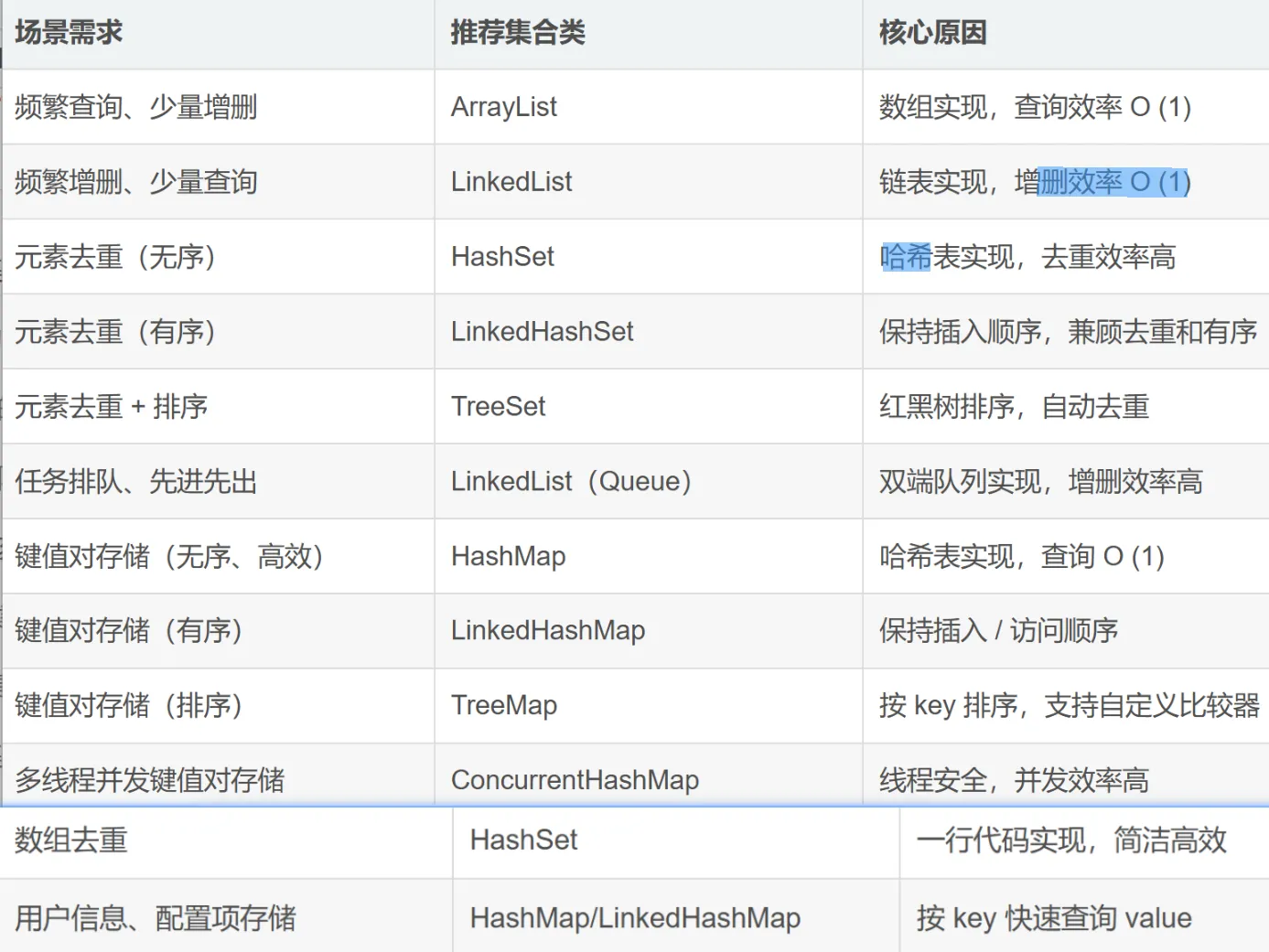
避坑指南
1.ArrayList 遍历中删除元素:使用普通 for 循环删除会导致索引错位,推荐使用迭代器(Iterator.remove())或增强 for 循环配合标记; 2.HashMap 的 key 必须重写 equals () 和 hashCode ():自定义对象作为 key 时,需重写这两个方法,否则无法保证去重正确性; 3.HashSet/HashMap 无序性:不要依赖遍历顺序,若需有序请使用 LinkedHashSet/LinkedHashMap; 4.线程安全问题:ArrayList、HashMap、HashSet 等都是线程不安全的,多线程环境下需ConcurrentHashMap、CopyOnWriteArrayList 等线程安全集合,或手动加锁; 5.TreeSet/TreeMap 的 key 必须可比较:自定义对象作为 key 时,需实现 Comparable 接口或传入 Comparator,否则抛出 ClassCastException。
Stream流
初识stream流
对集合(Collection)对象功能的增强,与Lambda表达式结合,可以提高编程效率、间接性和程序可读性。
特点
1、代码简洁:函数式编程写出的代码简洁且意图明确,使用stream接口让你从此告别for循环
2、多核友好:Java函数式编程使得编写并行程序如此简单,就是调用一下方法
流程
1、将集合转换为Stream流(或者创建流)
2、操作Stream流(中间操作,终端操作)
stream流在管道中经过中间操作(intermediate operation)的处理,最后由最终操作(terminal operation)得到前面处理的结果
方法引用
函数式接口和Lambda表达式
初识函数式接口
只有唯一一个抽象方法的接口
-
可以有默认方法、静态方法
-
只能有1个 abstract 抽象方法
1.作用
专门给 Lambda 表达式用 不是函数式接口 → 不能用Lambda简化
2.内置常用4大函数式接口
3.Consumer 消费型:有参无返回 void accept(T t)
Supplier 供给型:无参有返回 T get()
Function 函数型:有参有返回 R apply(T t)
Predicate 判断型:有参返回布尔 boolean test(T t)
- 一句话记
一抽象、可默认、标注解、配Lambda
5.对比
-
普通接口:多个抽象方法 → 只能匿名内部类
-
函数式接口:一个抽象方法 → 优先Lambda
初识Lambda表达式
Lambda 是匿名内部类的简化写法,只用于函数式接口(有且仅有一个抽象方法)
// 函数式接口interface Run { void go();}
// 匿名内部类Run r = new Run() { @Override public void go() { System.out.println("跑起来"); }};
//lambda表达式写法Run r = () -> System.out.println("跑起来");-
无参: () -> 代码
-
有参: (a,b) -> 代码
-
单参可省略括号: a -> 代码
-
多行代码用 {}
匿名内部类:生成独立.class文件 Lambda:不生成额外class,效率更高
this 含义 匿名内部类:指向内部类对象 Lambda:指向外层类对象
流创建操作
Stream创建
List<String> list = new ArrayList<>();Stream<String> stream = list.stream(); //串行流Stream<String> parallelStream = list.parallelStream(); //并行流
Stream<Integer> stream1 = Stream.of(1,2,3,4,5);Collection集合创建
List<Integer> integerList = new ArrayList<>(); integerList.add(1); integerList.add(2); integerList.add(3); integerList.add(4); integerList.add(5); Stream<Integer> listStream = integerList.stream();Array数组创建
int[] intArr = {1, 2, 3, 4, 5}; IntStream arrayStream = Arrays.stream(intArr);数值流与对象流转换
通过Arrays.stream方法生成流,并且该方法生成的流是数值流【即IntStream】而不是 Stream
注:****
使用数值流可以避免计算过程中拆箱装箱,提高性能。
Stream API提供了mapToInt、mapToDouble、mapToLong三种方式将对象流【即Stream 】转换成对应的数值流,同时提供了boxed方法将数值流转换为对象流
文件创建
try { Stream<String> fileStream = Files.lines(Paths.get("data.txt"), Charset.defaultCharset()); } catch (IOException e) { e.printStackTrace(); }//通过Files.line方法得到一个流,并且得到的每个流是给定文件中的一行函数创建
iterator
Stream<Integer> iterateStream = Stream.iterate(0, n -> n + 2).limit(5);//iterate方法接受两个参数,第一个为初始化值,第二个为进行的函数操作,因为iterator生成的流为无限流,通过limit方法对流进行了截断 ,只生成5个偶数generator
Stream<Double> generateStream = Stream.generate(Math::random).limit(5);//generate方法接受一个参数,方法参数类型为Supplier ,由它为流提供值。generate生成的流也是无限流,因此通过limit对流进行了截断Stream中的静态方法:of()、iterate()、generate()
Stream<Integer> stream = Stream.of(1,2,3,4,5,6);stream.forEach(System.out::println);// 输出:1 2 3 4 5 6
Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 2).limit(6);stream2.forEach(System.out::println);// 输出:0 2 4 6 8 10
Stream<Double> stream3 = Stream.generate(Math::random).limit(2);stream3.forEach(System.out::println);// 输出:两个随机数BufferedReader.lines() 方法,将每行内容转成流
BufferedReader reader = new BufferedReader(new FileReader("F:\\test_stream.txt"));Stream<String> lineStream = reader.lines();lineStream.forEach(System.out::println);Pattern.splitAsStream() 方法,将字符串分隔成流
Pattern pattern = Pattern.compile(",");Stream<String> stringStream = pattern.splitAsStream("a,b,c,d");stringStream.forEach(System.out::println);//输出:a b c d操作符
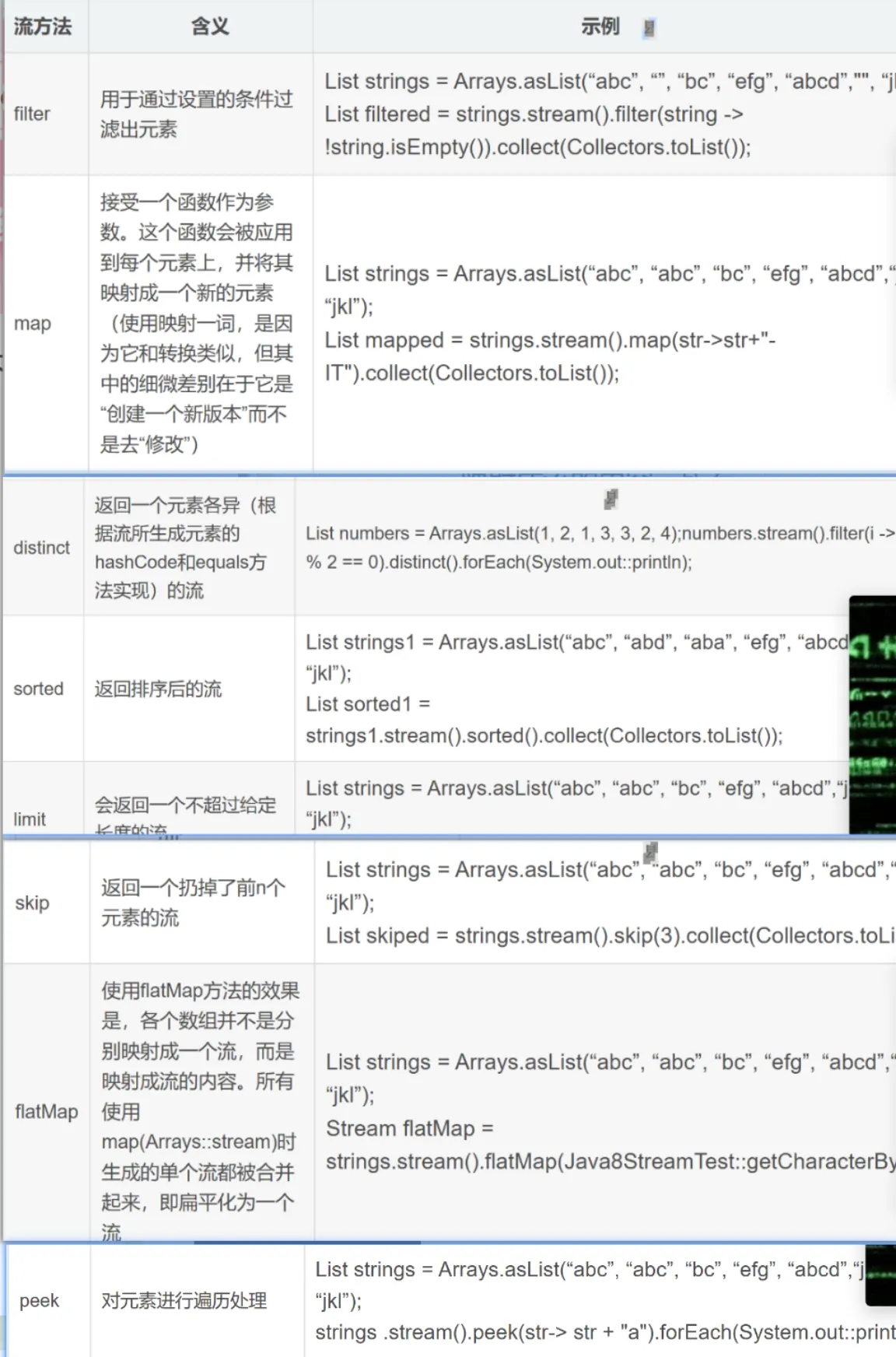
中间操作符
public static void main(String[] args) { List<User> userList = getUserList(); }
private static List<User> getUserList() { List<User> userList = new ArrayList<>();
userList.add(new User(1,"张三",18,"上海")); userList.add(new User(2,"王五",16,"上海")); userList.add(new User(3,"李四",20,"上海")); userList.add(new User(4,"张雷",22,"北京")); userList.add(new User(5,"张超",15,"深圳")); userList.add(new User(6,"李雷",24,"北京")); userList.add(new User(7,"王爷",21,"上海")); userList.add(new User(8,"张三丰",18,"广州")); userList.add(new User(9,"赵六",16,"广州")); userList.add(new User(10,"赵无极",26,"深圳"));
return userList; }//泛型可承接javabean实体类filter过滤
用于通过设置的条件过滤出元素
//1、filter:输出ID大于6的user对象List<User> filetrUserList = userList.stream().filter(user -> user.getId() > 6).collect(Collectors.toList());filetrUserList.forEach(System.out::println);根据对象属性去重
//set集合元素不可重复List<User> list = new ArrayList<User>() {{ add(new User("Tony", 20, "12")); add(new User("Pepper", 20, "123")); add(new User("Tony", 22, "1234")); add(new User("Tony", 22, "12345"));}};
//只通过名字去重List<User> streamByNameList = list.stream().collect(Collectors.collectingAndThen( Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(User::getName))), ArrayList::new));System.out.println(streamByNameList);//[User{name='Pepper', age=20, Phone='123'},// User{name='Tony', age=20, Phone='12'}]
//通过名字和年龄去重List<User> streamByNameAndAgeList = list.stream().collect(Collectors.collectingAndThen( Collectors.toCollection(() -> new TreeSet<>(Comparator.comparing(o -> o.getName() + o.getAge()))), ArrayList::new));System.out.println(streamByNameAndAgeList);//[User{name='Pepper', age=20, Phone='123'},// User{name='Tony', age=20, Phone='12'},// User{name='Tony', age=22, Phone='1234'}]//collectingAndThen 这个方法的意思是: 将收集的结果转换为另一种类型。
//因此上面的方法可以理解为:把 new TreeSet<>(Comparator.comparingLong(BookInfoVo::getRecordId))这个set转换为 ArrayLismap:映射
映射
接受一个函数作为参数。这个函数会被应用到每个元素上,并将其映射成一个新的元素(使用映射一词,是因为它和转换类似,但其中的细微差别在于它是“创建一个新版本”而不是去“修改”)
//2、mapList<String> mapUserList = userList.stream().map(user -> user.getName() + "用户").collect(Collectors.toList());mapUserList.forEach(System.out::println);//张三用户//王五用户//李四用户//张雷用户//张超用户//李雷用户//王爷用户//张三丰用户新值类型和原来的元素的类型相同示例
List<String> list = Arrays.asList("a,b,c", "1,2,3");
//将每个元素转成一个新的且不带逗号的元素Stream<String> s1 = list.stream().map(s -> s.replaceAll(",", ""));s1.forEach(System.out::println);// abc 123
Stream<String> s2 = list.stream().flatMap(s -> { //将每个元素转换成一个stream String[] split = s.split(","); Stream<String> s3 = Arrays.stream(split); return s3;});s2.forEach(System.out::println);// a b c 1 2 3distinct:去重
返回一个元素各异(根据流所生成元素的hashCode和equals方法实现)的流
//3、distinct:去重List<String> distinctUsers = userList.stream().map(User::getCity).distinct().collect(Collectors.toList());distinctUsers.forEach(System.out::println);sorted:排序
认识排序
自然排序(从小到大),流中元素需实现Comparable接口。 例:list.stream().sorted()
定制排序。常用以下几种: list.stream().sorted(Comparator.reverseOrder()) //倒序排序(从大到小) list.stream().sorted(Comparator.comparing(Student::getAge)) //顺序排序(从小到大) list.stream().sorted(Comparator.comparing(Student::getAge).reversed()) // 倒序排序(从大到小)
对象单字段排序
User u1 = new User("dd", 40);User u2 = new User("bb", 20);User u3 = new User("aa", 20);User u4 = new User("aa", 30);List<User> userList = Arrays.asList(u1, u2, u3, u4);
//按年龄升序userList.stream().sorted(Comparator.comparing(User::getAge)) .forEach(System.out::println);
//结果User(name=bb, age=20)User(name=aa, age=20)User(name=aa, age=30)User(name=dd, age=40)对象多字段、全部升序排序
//先按年龄升序,年龄相同则按姓名升序User u1 = new User("dd", 40);User u2 = new User("bb", 20);User u3 = new User("aa", 20);User u4 = new User("aa", 30);List<User> userList = Arrays.asList(u1, u2, u3, u4);
// 写法1(推荐)userList.stream().sorted(Comparator .comparing(User::getAge) .thenComparing(User::getName) // 可以写多个.thenComparing).forEach(System.out::println);
System.out.println("------------------------------------");
// 写法2userList.stream().sorted( (o1, o2) -> { String tmp1 = o1.getAge() + o1.getName(); String tmp2 = o2.getAge() + o2.getName(); return tmp1.compareTo(tmp2); }).forEach(System.out::println);
System.out.println("------------------------------------");
// 写法3userList.stream().sorted( (o1, o2) -> { if (!o1.getAge().equals(o2.getAge())) { return o1.getAge().compareTo(o2.getAge()); } else { return o1.getName().compareTo(o2.getName()); } }).forEach(System.out::println);
//结果User(name=aa, age=20)User(name=bb, age=20)User(name=aa, age=30)User(name=dd, age=40)对象多字段、升序+降序
//先按年龄升序,年龄相同则按姓名降序User u1 = new User("dd", 40);User u2 = new User("bb", 20);User u3 = new User("aa", 20);User u4 = new User("aa", 30);List<User> userList = Arrays.asList(u1, u2, u3, u4);
userList.stream().sorted( (o1, o2) -> { if (!o1.getAge().equals(o2.getAge())) { return o1.getAge().compareTo(o2.getAge()); } else { return o2.getName().compareTo(o1.getName()); } }).forEach(System.out::println);
//结果User(name=bb, age=20)User(name=aa, age=20)User(name=aa, age=30)User(name=dd, age=40)limit
//5、limit:取前5条数据userList.stream().limit(5).collect(Collectors.toList()).forEach(System.out::println);skip
//6、skip:跳过第几条取后几条userList.stream().skip(7).collect(Collectors.toList()).forEach(System.out::println);flatMap
flatmap与map的区别
使用flatMap方法的效果是,各个数组并不是分别映射成一个流,而是映射成流的内容。所有使用map(Arrays::stream)时生成的单个流都被合并起来,即扁平化为一个流
map:对流中每一个元素进行处理 flatMap:流扁平化,让你把一个流中的“每个值”都换成另一个流,然后把所有的流连接起来成为一个流 本质区别:map是对一级元素进行操作,flatmap是对二级元素操作map返回一个值;flatmap返回一个流,多个值
应用场景:map对集合中每个元素加工,返回加工后结果;flatmap对集合中每个元素加工后,做扁平化处理后(拆分层级,放到同一层)然后返回
//7、flatMap:数据拆分一对多映射userList.stream().flatMap(user -> Arrays.stream(user.getCity().split(","))).forEach(System.out::println);peek遍历
//8、peek:对元素进行遍历处理,每个用户ID加1输出userList.stream().peek(user -> user.setId(user.getId()+1)).forEach(System.out::println);终端操作符
认识终端操作符
Stream流执行完终端操作之后,无法再执行其他动作,否则会报状态异常,提示该流已经被执行操作或者被关闭,想要再次执行操作必须重新创建Stream流
一个流有且只能有一个终端操作,当这个操作执行后,流就被关闭了,无法再被操作,因此一个流只能被遍历一次,若想在遍历需要通过源数据在生成流。
终端操作的执行,才会真正开始流的遍历。如 count、collect 等
collect
收集器,将流转换为其他形式
//1、collect:收集器,将流转换为其他形式 Set set = userList.stream().collect(Collectors.toSet()); set.forEach(System.out::println); System.out.println("--------------------------"); List list = userList.stream().collect(Collectors.toList()); list.forEach(System.out::println);forEach
//2、forEach:遍历流userList.stream().forEach(user -> System.out.println(user));userList.stream().filter(user -> "上海".equals(user.getCity())).forEach(System.out::println);findFirst和findAny
//3、findFirst:返回第一个元素User firstUser = userList.stream().findFirst().get();User firstUser1 = userList.stream().filter(user -> "上海".equals(user.getCity())).findFirst().get();//4、findAny:将返回当前流中的任意元素User findUser = userList.stream().findAny().get();User findUser1 = userList.stream().filter(user -> "上海".equals(user.getCity())).findAny().get();
//5、count:返回流中元素总数long count = userList.stream().filter(user -> user.getAge() > 20).count();System.out.println(count);//6、sum:求和int sum = userList.stream().mapToInt(User::getId).sum();//7、max:最大值int max = userList.stream().max(Comparator.comparingInt(User::getId)).get().getId();//8、min:最小值int min = userList.stream().min(Comparator.comparingInt(User::getId)).get().getId();Collect收集
toList
//将用户ID存放到List集合中List<Integer> idList = userList.stream().map(User::getId).collect(Collectors.toList()) ;toMap
Map<Integer,String> userMap = userList.stream().collect(Collectors.toMap(User::getId,User::getName));toset
Set<String> citySet = userList.stream().map(User::getCity).collect(Collectors.toSet());counting
//符合条件的用户总数long count = userList.stream().filter(user -> user.getId()>1).collect(Collectors.counting());summingInt
对结果元素即用户ID求和
Integer sumInt = userList.stream().filter(user -> user.getId()>2).collect(Collectors.summingInt(User::getId)) ;minBy
筛选元素中ID最小的用户
User maxId = userList.stream().collect(Collectors.minBy(Comparator.comparingInt(User::getId))).get() ;joining
将用户所在城市,以指定分隔符链接 成字符串;
String joinCity = userList.stream().map(User::getCity).collect(Collectors.joining("||"));IO流
IO流概述
初识IO流
数据的传输可以看做是一种数据的流动,按照流动的方向,以内存为基准,分为`输入input` 和`输出output` ,即流向内存是输入流,流出内存的输出流。Java中I/O操作主要是指使用java.io包下的内容,进行输入、输出操作。输入也叫做读取数据,输出也叫做作写出数据。
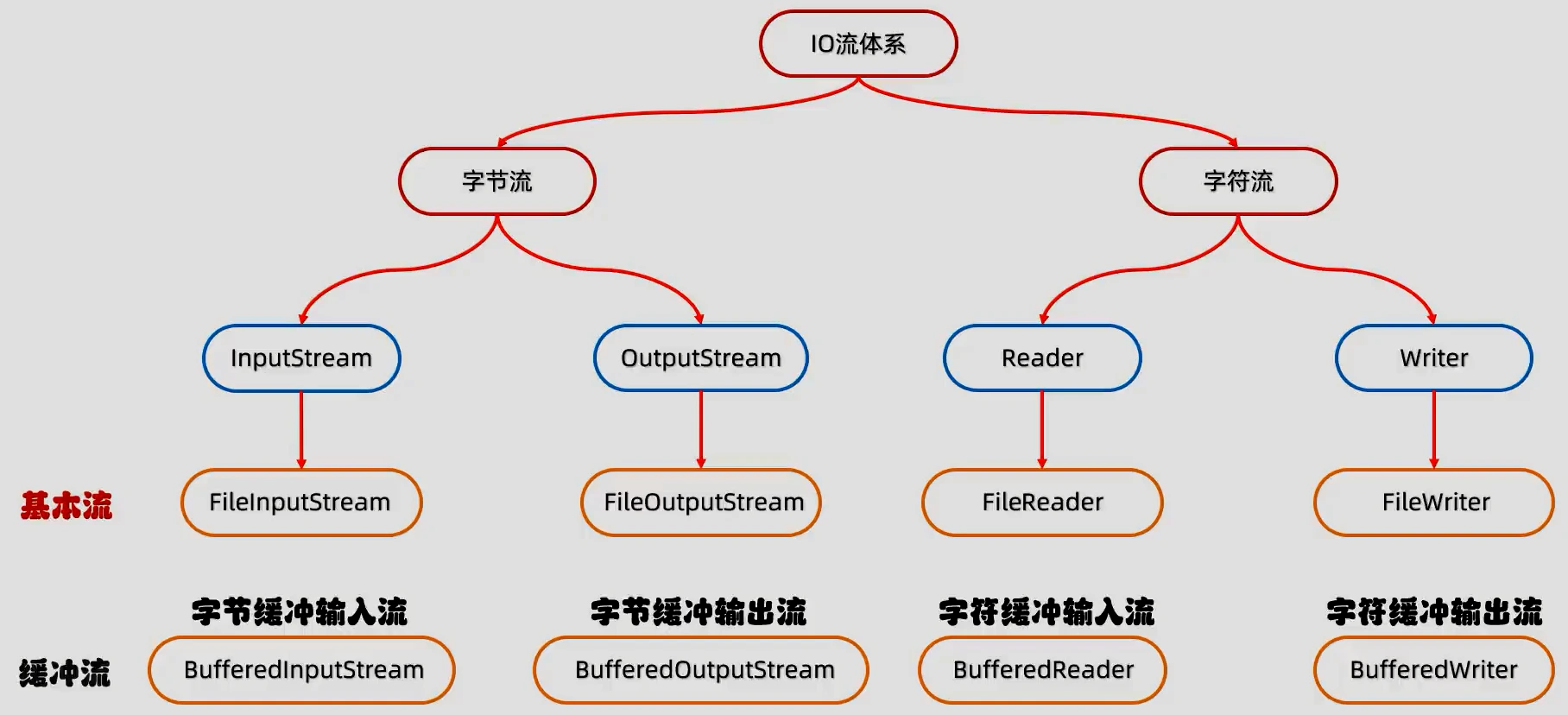
根据数据的流向分为:输入流和输出流。
- 输入流 :把数据从
其他设备上读取到内存中的流。 - 输出流 :把数据从
内存中写出到其他设备上的流。
格局数据的类型分为:字节流和字符流。
- 字节流 :以字节为单位,读写数据的流。
- 字符流 :以字符为单位,读写数据的流
顶级父类
| 输入流 | 输出流 | |
|---|---|---|
| 字节流 | 字节输入流InputStream | 字节输出流OutputStream |
| 字符流 | 字符输入流Reader | 字符输出流Writer |
一个简单的方法判断文件存储是否是字符流:将文件使用Windows 自带的文本编辑器打开,能直接看懂的是字符流,不能直接看懂的(比如乱码)是字节流。
字节流
字节流读取文件的时候,文件中不要有中文。
一切文件数据(文本、图片、视频等)在存储时,都是以二进制数字的形式保存,都一个一个的字节,那么传输时一样如此。所以,字节流可以传输任意文件数据
字节输出流OutputStream
初识字节输出流
java.io.OutputStream 抽象类是表示字节输出流的所有类的超类,将指定的字节信息写出到目的地。它定义了字节输出流的基本共性功能方法。
public void close() :关闭此输出流并释放与此流相关联的任何系统资源。 public void flush() :刷新此输出流并强制任何缓冲的输出字节被写出。 public void write(byte[] b):将 b.length字节从指定的字节数组写入此输出流。 public void write(byte[] b, int off, int len) :从指定的字节数组写入 len字节,从偏移量 off开始输出到此输出流。 public abstract void write(int b) :将指定的字节输出流。 对于close方法:当完成流的操作时,必须调用此方法,释放系
FileOutputStream类
认识fileoutstream
OutputStream有很多子类,从最简单的一个子类开始。java.io.FileOutputStream 类是文件输出流,用于将数据写出到文件。
2.3.1 构造方法 public FileOutputStream(File file):创建文件输出流以写入由指定的 File对象表示的文件。 public FileOutputStream(String name): 创建文件输出流以指定的名称写入文件。 当你创建一个流对象时,必须传入一个文件路径 。该路径下,如果没有这个文件,会创建该文件。如果有这个文件,会清空这个文件的数据。
public class FileOutputStreamConstructor throws IOException { public static void main(String[] args) { // 使用File对象创建流对象 File file = new File("a.txt"); FileOutputStream fos = new FileOutputStream(file);
// 使用文件名称创建流对象 FileOutputStream fos = new FileOutputStream("b.txt"); }}写出字节:write(int b)
public class FileOutputStreamDemo01 { public static void main(String[] args) throws IOException { //1.创建对象 //写出 输出流 OutputStream //本地文件 File FileOutputStream fos = new FileOutputStream("my-io\\a.txt"); //2.写出数据 fos.write(97); //3.释放资源 fos.close(); }}//每次可以写出一个字节数据写出字节数组:write(byte[] b)
public class FileOutputStreamDemo03 { public static void main(String[] args) throws IOException { //1.创建对象 FileOutputStream fos = new FileOutputStream("my-io\\a.txt"); //2.一次写一个字节数组数据 byte[] bytes = {97, 98, 99, 100, 101}; fos.write(bytes); //4.释放资源 fos.close(); }}写出指定长度字节数组:write(byte[] b, int off, int len)
public class FileOutputStreamDemo03 { public static void main(String[] args) throws IOException { //1.创建对象 FileOutputStream fos = new FileOutputStream("my-io\\a.txt"); //2.一次写一个字节数组数据 byte[] bytes = {97, 98, 99, 100, 101}; //3.一次写一个字节数组的部分数据 fos.write(bytes,1,2); // b c //4.释放资源 fos.close(); }}//参数一:数组//参数二:起始索引//参数三:个数数据追加续写
经过以上的演示,每次程序运行,创建输出流对象,都会清空目标文件中的数据。需要在构造方法的参数传入一个boolean类型的值,true 表示追加数据,false 表示清空原有数据。这样创建的输出流对象,就可以指定是否追加续写了。
public FileOutputStream(File file, boolean append): 创建文件输出流以写入由指定的 File对象表示的文件。 public FileOutputStream(String name, boolean append): 创建文件输出流以指定的名称写入文件。
public class FileOutputStreamDemo04 { public static void main(String[] args) throws IOException { //1.创建对象,开启续写 FileOutputStream fos = new FileOutputStream("my-io\\a.txt",true); //2.写出数据 String str = "Hello"; byte[] bytes = str.getBytes(); fos.write(bytes); //3.释放资源 fos.close(); }}//bchello写出换行
public class FileOutputStreamDemo04 { public static void main(String[] args) throws IOException { // 使用文件名称创建流对象 FileOutputStream fos = new FileOutputStream("my-io\\a.txt"); // 定义字节数组 byte[] words = {97,98,99,100,101}; // 遍历数组 for (int i = 0; i < words.length; i++) { // 写出一个字节 fos.write(words[i]); // 写出一个换行, 换行符号转成数组写出 fos.write("\r\n".getBytes()); } // 关闭资源 fos.close(); }}字节输入流 InputStream
初识字节输入流
java.io.InputStream 抽象类是表示字节输入流的所有类的超类,可以读取字节信息到内存中。它定义了字节输入流的基本共性功能方法。
public void close() :关闭此输入流并释放与此流相关联的任何系统资源。 public abstract int read(): 从输入流读取数据的下一个字节。 public int read(byte[] b): 从输入流中读取一些字节数,并将它们存储到字节数组 b中 。 close方法,当完成流的操作时,必须调用此方法,释放系统资源
FileInputStream类
初识
初识fileoutstream
java.io.FileInputStream 类是文件输入流,从文件中读取字节。
2.5.1 构造方法 创建一个流对象时,必须传入一个文件路径。该路径下,如果没有该文件,会抛出FileNotFoundException 。
FileInputStream(File file): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的 File对象 file命名。 FileInputStream(String name): 通过打开与实际文件的连接来创建一个 FileInputStream ,该文件由文件系统中的路径名 name命名。
public class FileInputStreamConstructor throws IOException{ public static void main(String[] args) { // 使用File对象创建流对象 File file = new File("a.txt"); FileInputStream fos = new FileInputStream(file);
// 使用文件名称创建流对象 FileInputStream fos = new FileInputStream("b.txt"); }}读取字节数据
public class FileInputStreamDemo01 { public static void main(String[] args) throws IOException { //1.创建对象 FileInputStream fis = new FileInputStream("my-io\\a.txt"); //2.读取数据,返回一个字节 int read = fis.read(); System.out.println((char) read); read = fis.read(); System.out.println((char) read); read = fis.read(); System.out.println((char) read); read = fis.read(); System.out.println((char) read); read = fis.read(); System.out.println((char) read); // 读取到末尾,返回-1 read = fis.read(); System.out.println( read); //3.关闭资源 fis.close(); }}//read方法,每次可以读取一个字节的数据,提升为int类型,读取到文件末尾,返回-1//a,b,c,d,-1循环读取
public class FileInputStreamDemo03 { public static void main(String[] args) throws IOException { // 使用文件名称创建流对象 FileInputStream fis = new FileInputStream("my-io\\a.txt"); // 定义变量,保存数据 int b; // 循环读取 while ((b = fis.read()) != -1) { System.out.println((char) b); } // 关闭资源 fis.close(); }}使用字节数组读取
public class FileInputStreamDemo05 { public static void main(String[] args) throws IOException {
//1.创建对象 FileInputStream fis = new FileInputStream("my-io\\a.txt"); //2.读取数据 byte[] bytes = new byte[2]; //一次读取多个字节数据,具体读多少,跟数组的长度有关 //返回值:本次读取到了多少个字节数据 int len1 = fis.read(bytes); System.out.println(len1);//2 String str1 = new String(bytes,0,len1); System.out.println(str1);//ab
int len2 = fis.read(bytes); System.out.println(len2);//2 String str2 = new String(bytes,0,len2); System.out.println(str2);//cd
int len3 = fis.read(bytes); System.out.println(len3);// 1 String str3 = new String(bytes,0,len3); System.out.println(str3);//e
//3.释放资源 fis.close(); }}文件拷贝
public class FileInputStreamDemo04 { public static void main(String[] args) throws IOException { long start = System.currentTimeMillis();
//1.创建对象 FileInputStream fis = new FileInputStream("D:\\aaa\\movie.mp4"); FileOutputStream fos = new FileOutputStream("my-io\\copy.mp4"); //2.拷贝 //核心思想:边读边写 int b; while((b = fis.read()) != -1){ fos.write(b); } //3.释放资源 //规则:先开的最后关闭 fos.close(); fis.close();
long end = System.currentTimeMillis(); System.out.println(end - start); }}public class FileInputStreamDemo06 { public static void main(String[] args) throws IOException { long start = System.currentTimeMillis();
//1.创建对象 FileInputStream fis = new FileInputStream("D:\\aaa\\movie.mp4"); FileOutputStream fos = new FileOutputStream("my-io\\copy.mp4"); //2.拷贝 int len; byte[] bytes = new byte[1024 * 1024 * 5]; while((len = fis.read(bytes)) != -1){ fos.write(bytes,0,len); } //3.释放资源 fos.close(); fis.close();
long end = System.currentTimeMillis(); System.out.println(end - start); }}字符流
初识字符流
当使用字节流读取文本文件时,可能会有一个小问题。就是遇到中文字符时,可能不会显示完整的字符,那是因为一个中文字符可能占用多个字节存储。所以Java提供一些字符流类,以字符为单位读写数据,专门用于处理文本文件。
字符输入流 Reader
java.io.Reader抽象类是表示用于读取字符流的所有类的超类,可以读取字符信息到内存中。它定义了字符输入流的基本共性功能方法。
public void close() :关闭此流并释放与此流相关联的任何系统资源。 public int read(): 从输入流读取一个字符。 public int read(char[] cbuf): 从输入流中读取一些字符,并将它们存储到字符数组 cbuf中
FileReader类
初识filereader
java.io.FileReader 类是读取字符文件的便利类。构造时使用系统默认的字符编码和默认字节缓冲区。
字符编码:字节与字符的对应规则。Windows系统的中文编码默认是GBK编码表;idea中是Unicode字符集、UTF-8编码 字节缓冲区:一个字节数组,用来临时存储字节数
创建一个流对象时,必须传入一个文件路径,类似于FileInputStream 。
FileReader(File file): 创建一个新的 FileReader ,给定要读取的File对象。 FileReader(String fileName): 创建一个新的 FileReader ,给定要读取的文件的名称。
public class FileReaderConstructor throws IOException{ public static void main(String[] args) { // 使用File对象创建流对象 File file = new File("a.txt"); FileReader fr = new FileReader(file);
// 使用文件名称创建流对象 FileReader fr = new FileReader("b.txt"); }}读取字符数据
第一步:创建对象public FileReader(File file) 创建字符输入流关联本地文件public FileReader(String pathname) 创建字符输入流关联本地文件第二步:读取数据public int read() 读取数据,读到末尾返回-1public int read(char[] buffer) 读取多个数据,读到末尾返回-1第三步:释放资源public void close() 释放资源/关流public class FileReaderDemo01 { public static void main(String[] args) throws IOException {
//1.创建对象并关联本地文件 FileReader fr = new FileReader("my-io\\a.txt");
/** * 2.读取数据 read() * 字符流的底层也是字节流,默认也是一个字节一个字节的读取的。 * 如果遇到中文就会一次读取多个,GBK一次读两个字节,UTF-8一次读三个字节 * read()细节: * 1.read():默认也是一个字节一个字节的读取的,如果遇到中文就会一次读取多个 * 2.在读取之后,方法的底层还会进行解码并转成十进制。 * 最终把这个十进制作为返回值,这个十进制的数据也表示在字符集上的数字 * 英文:文件里面二进制数据 0110 0001 * read方法进行读取,解码并转成十进制97 * 中文:文件里面的二进制数据 11100110 10110001 10001001 * read方法进行读取,解码并转成十进制27721 * 想看到中文汉字,就是把这些十进制数据,再进行强转就可以了 */
// 循环读取 int ch; while((ch = fr.read()) != -1){ System.out.println((char)ch); } //3.释放资源 fr.close(); }}//虽然读取了一个字符,但是会自动提升为int类型。使用字符数组读取:
public class FileReaderDemo02 { public static void main(String[] args) throws IOException {
//1.创建对象 FileReader fr = new FileReader("my-io\\a.txt"); //2.读取数据 char[] chars = new char[2]; int len; // 获取有效的字符 //read(chars):读取数据,解码,强转三步合并了,把强转之后的字符放到数组当中 //空参的read + 强转类型转换 while((len = fr.read(chars)) != -1){ // 把数组中的数据变成字符串再进行打印 System.out.println(new String(chars,0,len)); } //3.释放资源 fr.close(); }}字符输出流 Writer
初识字符输出流
java.io.Writer 抽象类是表示用于写出字符流的所有类的超类,将指定的字符信息写出到目的地。它定义了字节输出流的基本共性功能方法。
void write(int c) 写入单个字符。 void write(char[] cbuf) 写入字符数组。 abstract void write(char[] cbuf, int off, int len) 写入字符数组的某一部分,off数组的开始索引,len写的字符个数。 void write(String str) 写入字符串。 void write(String str, int off, int len) 写入字符串的某一部分,off字符串的开始索引,len写的字符个数。 void flush() 刷新该流的缓冲。 void close() 关闭此流,但要先刷新它。
基本写出数据
public class FWWrite { public static void main(String[] args) throws IOException { // 使用文件名称创建流对象 FileWriter fw = new FileWriter("fw.txt"); // 写出数据 fw.write(97); // 写出第1个字符 fw.write('b'); // 写出第2个字符 fw.write('C'); // 写出第3个字符 fw.write(30000); // 写出第4个字符,中文编码表中30000对应一个汉字。
/* 【注意】关闭资源时,与FileOutputStream不同。 如果不关闭,数据只是保存到缓冲区,并未保存到文件。 */ // fw.close(); }}输出结果:abC田//虽然参数为int类型四个字节,但是只会保留一个字符的信息写出。//未调用close方法,数据只是保存到了缓冲区,并未写出到文件中。关闭和刷新
因为内置缓冲区的原因,如果不关闭输出流,无法写出字符到文件中。但是关闭的流对象,是无法继续写出数据的。如果既想写出数据,又想继续使用流,就需要flush 方法了。
flush :刷新缓冲区,流对象可以继续使用。 close :先刷新缓冲区,然后通知系统释放资源,流对象不可以再被使用了。
public class FWWrite { public static void main(String[] args) throws IOException { // 使用文件名称创建流对象 FileWriter fw = new FileWriter("fw.txt"); // 写出数据,通过flush fw.write('刷'); // 写出第1个字符 fw.flush(); fw.write('新'); // 继续写出第2个字符,写出成功 fw.flush();
// 写出数据,通过close fw.write('关'); // 写出第1个字符 fw.close(); fw.write('闭'); // 继续写出第2个字符,【报错】java.io.IOException: Stream closed fw.close(); }}写出字符数组 :
public class FileWriterDemo01 { public static void main(String[] args) throws IOException { // 创建流对象并开启续写 FileWriter fw = new FileWriter("my-io\\a.txt",true);
//fw.write(25105); //fw.write("你好威啊???"); char[] chars = {'a','b','c','我'}; fw.write(chars);
fw.close(); }}写出字符串
public class FileWriterDemo03 { public static void main(String[] args) throws IOException {
// 创建流对象,未开启续写 FileWriter fw = new FileWriter("my-io\\a.txt");
fw.write("我的同学各个都很厉害"); fw.write("说话声音很好听");
fw.flush();
fw.write("都是人才"); fw.write("超爱这里哟");
fw.close(); }}IO流异常处理
JDK7后
public class TryDemo { public static void main(String[] args) throws IOException { // 创建流对象 final FileReader fr = new FileReader("in.txt"); FileWriter fw = new FileWriter("out.txt"); // 引入到try中 try (fr; fw) { // 定义变量 int b; // 读取数据 while ((b = fr.read())!=-1) { // 写出数据 fw.write(b); } } catch (IOException e) { e.printStackTrace(); } }}缓冲流
字节缓冲流概述
初识缓冲流
缓冲流,也叫高效流,是对4个基本的FileXxx 流的增强,所以也是4个流,按照数据类型分类:
字节缓冲流:BufferedInputStream,BufferedOutputStream 字符缓冲流:BufferedReader,BufferedWriter 缓冲流的基本原理,是在创建流对象时,会创建一个内置的默认大小的缓冲区数组,通过缓冲区读写,减少系统IO次数,从而提高读写的效率。
// 创建字节缓冲输入流BufferedInputStream bis = new BufferedInputStream(new FileInputStream("bis.txt"));// 创建字节缓冲输出流BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("bos.txt"));public class BufferedDemo { public static void main(String[] args) throws FileNotFoundException { // 记录开始时间 long start = System.currentTimeMillis(); // 创建流对象 try ( FileInputStream fis = new FileInputStream("jdk9.exe"); FileOutputStream fos = new FileOutputStream("copy.exe") ){ // 读写数据 int b; while ((b = fis.read()) != -1) { fos.write(b); } } catch (IOException e) { e.printStackTrace(); } // 记录结束时间 long end = System.currentTimeMillis(); System.out.println("普通流复制时间:"+(end - start)+" 毫秒"); }}
十几分钟过去了...public class BufferedDemo { public static void main(String[] args) throws FileNotFoundException { // 记录开始时间 long start = System.currentTimeMillis(); // 创建流对象 try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jdk9.exe")); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe")); ){ // 读写数据 int b; while ((b = bis.read()) != -1) { bos.write(b); } } catch (IOException e) { e.printStackTrace(); } // 记录结束时间 long end = System.currentTimeMillis(); System.out.println("缓冲流复制时间:"+(end - start)+" 毫秒"); }}
缓冲流复制时间:8016 毫秒public class BufferedDemo { public static void main(String[] args) throws FileNotFoundException { // 记录开始时间 long start = System.currentTimeMillis(); // 创建流对象 try ( BufferedInputStream bis = new BufferedInputStream(new FileInputStream("jdk9.exe")); BufferedOutputStream bos = new BufferedOutputStream(new FileOutputStream("copy.exe")); ){ // 读写数据 int len; byte[] bytes = new byte[8*1024]; while ((len = bis.read(bytes)) != -1) { bos.write(bytes, 0 , len); } } catch (IOException e) { e.printStackTrace(); } // 记录结束时间 long end = System.currentTimeMillis(); System.out.println("缓冲流使用数组复制时间:"+(end - start)+" 毫秒"); }}缓冲流使用数组复制时间:666 毫秒字符缓冲流
初识字符缓冲流
字符缓冲流的基本方法与普通字符流调用方式一致,不再阐述,我们来看它们具备的特有方法。
BufferedReader:public String readLine(): 读一行文字。 BufferedWriter:public void newLine(): 写一行行分隔符,由系统属性定义符号。
readline方法
public class BufferedStreamDemo03 { public static void main(String[] args) throws IOException { //1.创建字符缓冲输入流的对象 BufferedReader br = new BufferedReader(new FileReader("my-io\\a.txt"));
//2.读取数据 /*String line1 = br.readLine(); System.out.println(line1);
String line2 = br.readLine(); System.out.println(line2);*/
String line; while ((( line = br.readLine()) != null)){ System.out.println(line); } //3.释放资源 br.close(); }}//readLine方法在读取的时候,一次读一整行,遇到回车换行结束,但是不会把回车换行读到内存当中newLine方法
public class BufferedStreamDemo04 { public static void main(String[] args) throws IOException {
//1.创建字符缓冲输出流的对象 BufferedWriter bw = new BufferedWriter(new FileWriter("my-io/b.txt",true)); //2.写出数据 bw.write("你好"); bw.newLine(); bw.write("我是张三"); bw.newLine(); //3.释放资源 bw.close(); }}练习
文本排序
问题1

分析:
- 逐行读取文本信息。
- 把读取到的文本存储到集合中
- 对集合中的文本进行排序
- 遍历集合,按顺序,写出文本信息
public class Test06Case01 { public static void main(String[] args) throws IOException {
//1.读取数据 BufferedReader br = new BufferedReader(new FileReader("my-io\\csb.txt")); String line; ArrayList<String> list = new ArrayList<>(); while((line = br.readLine()) != null){ list.add(line); } br.close();
//2.排序 //排序规则:按照每一行前面的序号进行排列 Collections.sort(list, new Comparator<String>() { @Override public int compare(String o1, String o2) { //获取o1和o2的序号 int i1 = Integer.parseInt(o1.split("\\.")[0]); int i2 = Integer.parseInt(o2.split("\\.")[0]); return i1 - i2; } });
//3.写出 BufferedWriter bw = new BufferedWriter(new FileWriter("my-io\\csb-result.txt")); for (String str : list) { bw.write(str); bw.newLine(); } bw.close(); }}public class Test06Case02 { public static void main(String[] args) throws IOException {
//1.读取数据 BufferedReader br = new BufferedReader(new FileReader("my-io\\csb.txt")); String line; TreeMap<Integer,String> tm = new TreeMap<>(); while((line = br.readLine()) != null){ String[] arr = line.split("\\."); //0:序号 1 :内容 tm.put(Integer.parseInt(arr[0]),line); } br.close();
//2.写出数据 BufferedWriter bw = new BufferedWriter(new FileWriter("my-io\\csb-result2.txt")); Set<Map.Entry<Integer, String>> entries = tm.entrySet(); for (Map.Entry<Integer, String> entry : entries) { String value = entry.getValue(); bw.write(value); bw.newLine(); } bw.close(); }}程序运行次数限制
public class Test07 { public static void main(String[] args) throws IOException { //1.把文件中的数字读取到内存中 //创建IO流的原则:随用随创建,什么时候不用什么时候关闭 BufferedReader br = new BufferedReader(new FileReader("my-io\\count.txt")); String line = br.readLine(); br.close(); // 读完数据就关闭
int count = Integer.parseInt(line); //表示当前软件又运行了一次 count++;//1 //2.判断 if(count <= 3 && count >= 0){ System.out.println("欢迎使用本软件,第"+count+"次使用免费~"); }else{ System.out.println("本软件只能免费使用3次,欢迎您注册会员后继续使用~"); } BufferedWriter bw = new BufferedWriter(new FileWriter("my-io\\count.txt")); //3.把当前自增之后的count写出到文件当中 bw.write(count + ""); // 转成字符串 bw.close(); }}转换流
初识转换流
转换流提供了在字节流和字符流之间的转换 Java API提供了两个转换流:
- InputStreamReader:将InputStream转换为Reader
- 实现将字节的输入流按指定字符集转换为字符的输入流。
- 需要和InputStream“套接”。
- 构造器
- public InputStreamReader(InputStreamin)
- public InputSreamReader(InputStreamin,StringcharsetName)
- 如:Reader isr= new InputStreamReader(System.in,”gbk”);
- OutputStreamWriter:将Writer转换为OutputStream
- 实现将字符的输出流按指定字符集转换为字节的输出流。
- 需要和OutputStream“套接”。
- 构造器
- public OutputStreamWriter(OutputStreamout)
- public OutputSreamWriter(OutputStreamout,StringcharsetName)
字节流中的数据都是字符时,转成字符流操作更高效。
很多时候我们使用转换流来处理文件乱码问题。实现编码和解码的功能。
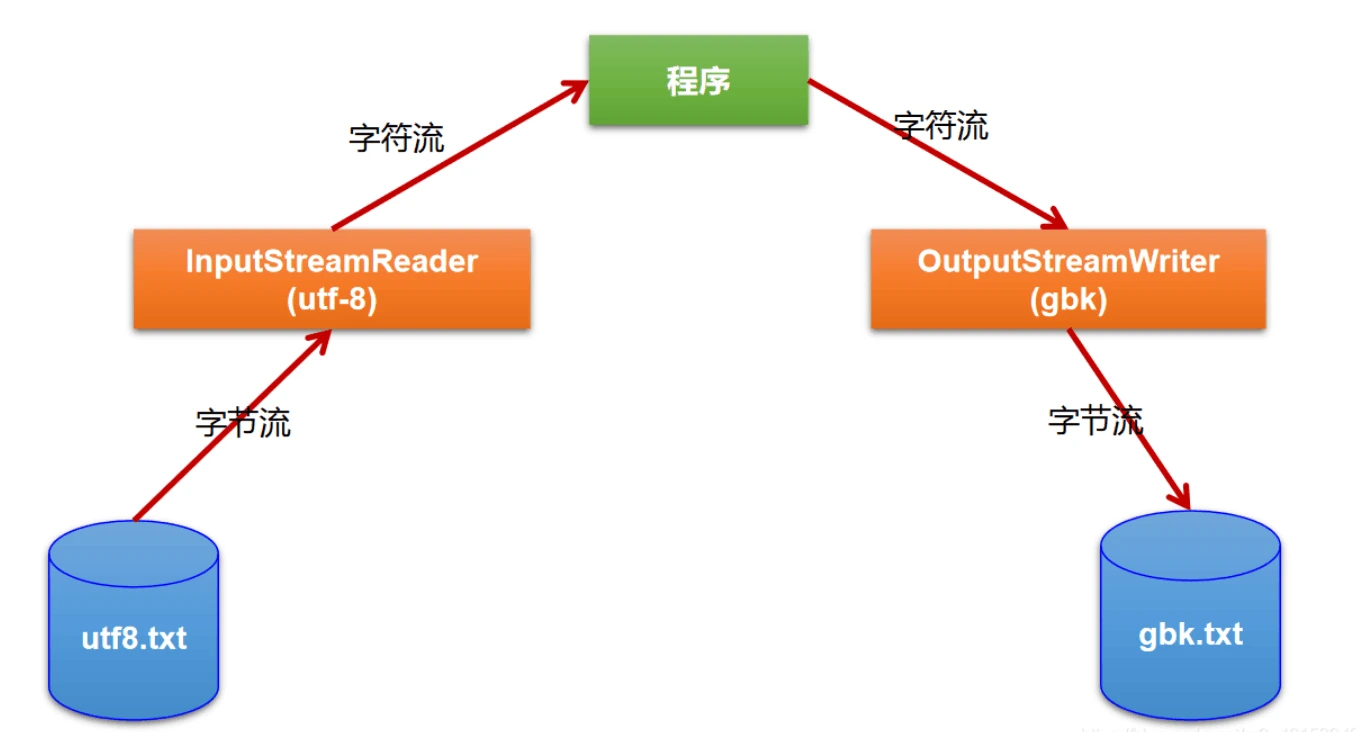
@Test public void test4() { File file1 = new File("hello.txt"); File file2 = new File("hello_gbk.txt"); FileInputStream fis = new FileInputStream(file1); FileOutputStream fos = new FileOutputStream(file2); InputStreamReader isr = new InputStreamReader(fis, "utf-8"); OutputStreamWriter osw = new OutputStreamWriter(fos, "gbk"); char[] chars = new char[1024]; int len; while ((len = isr.read()) != -1) { osw.write(chars, 0, len); } isr.close(); osw.close(); }多线程
初识多线程
- 程序:是为完成特定任务、用某种语言编写的一组指令的集合,即我们写的静态代码。
- 进程:
- 指运行中的程序。如启动QQ,操作系统会为其分配独立的内存空间。
- 进程是程序的一次执行过程,是动态的,有其产生、存在和消亡的生命周期。
- 线程:
- 由进程创建,是进程的一个实体。
- 一个进程可以拥有多个线程(如一个QQ进程可以同时打开多个聊天窗口)
- 单线程:同一时刻,只允许执行一个线程。
- 多线程:同一时刻,可以执行多个线程。
- 并发:单核CPU实现的多任务。同一时刻,多个任务交替执行,造成“同时”的错觉。
- 并行:多核CPU实现的多任务。同一时刻,多个任务真正同时执行。
继承Thread类
//1.创建一个继承于Thread类的子类class MyThread extends Thread{ //2.重写Thread的run()方法 @Override public void run() { for (int i = 0; i < 100; i++) { if(i%2==0){ System.out.println(Thread.currentThread().getName()+i); } } }}public class ThreadDemo{ public static void main(String[] args) { //方式1 //3.创建Thread类的子对象 MyThread mythread = new MyThread(); //此步骤是将创建的线程命名为"线程1-" 方便观察结果对比 mythread.setName("线程1-"); //4.通过此对象调用start() mythread.start();
//方式2 //创建Thread类的匿名子类的方式 new Thread(){ @Override public void run() { for (int i = 0; i < 500; i++) { if(i%10==0){ System.out.println(Thread.currentThread().getName()+i); } } } }.start();
//方式3 //JVM自动创建不需要 start //将main()命名为主线程- Thread.currentThread().setName("主线程-"); for (int i = 0; i < 100; i++) { if(i%2!=0){ System.out.println(Thread.currentThread().getName()+i); } } }}
部分运行结果:Thread-170Thread-180主线程-5线程1-36线程1-38主线程-7Thread-190Thread-1100···//每个线程都是通过某个特定的Thread对象的run()方法来完成操作的,通常把run()方法的主体称为线程体通过Thread对象的start()方法而不是run()方法来启动这个线程,而非直接调用run(
start() 方法会调用底层的 start0() 方法,使线程进入可运行状态,由CPU调度执行。直接调用 run() 方法仅是普通方法调用,不会启动新线程。
显而易见,三个线程的运行结果之间存在交叉(没有出现交叉的请多执行几遍)thread 类的相关方法
认识thread相关方法
start():启动当前线程,执行当前线程的run()
-
run():通常需要重写Thread类中的此方法,将创建的线程要执行的操作声明在此方法中
-
currentThread(): 静态方法,返回当前代码执行的线程
-
getName():获取当前线程的名字
-
setName():设置当前线程的名字
-
yield():释放当前CPU的执行权
-
join():在线程a中调用线程b的join(),此时线程a就进入阻塞状态,直到线程b完全执行完以后,线程a才结束阻塞状态。
-
stop():已过时。当执行此方法时,强制结束当前线程。
-
sleep(long millitime):让当前线程”睡眠”指定时间的millitime(毫秒)。在指定的millitime毫秒时间内,当前线程是阻塞状态的。
-
isAlive():返回boolean,判断线程是否还活着
public class ThreadDemo { public static void main(String[] args) { MyThread01 myThread01 = new MyThread01(); myThread01.start(); //输出线程存活状态 System.out.println(myThread01.isAlive()); for (int i = 0; i < 20; i++) { System.out.println("张" + i); try { //每次输出之后休眠10ms Thread.currentThread().sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } if (i == 10) { try { //输出张10之后,将myThread01线程执行完 myThread01.join(); } catch (InterruptedException e) { e.printStackTrace(); } } } //输出线程存活状态 System.out.println(myThread01.isAlive()); }
}
class MyThread01 extends Thread { @Override public void run() { for (int i = 0; i < 20; i++) { if (i == 2) { //当i==2时,释放当前CPU的执行权,等待分配 //也可以理解为抢球,谁抢到就谁执行 MyThread01.yield(); } try { sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(getName() + i); } }}
运行结果:true张0张1Thread-00Thread-01//yield释放cpu权限,两个线程抢占cpu张2张3Thread-02张4Thread-03Thread-04张5张6Thread-05Thread-06张7张8Thread-07张9Thread-08张10//join方法Thread-09Thread-010Thread-011Thread-012Thread-013Thread-014Thread-015Thread-016Thread-017Thread-018Thread-019张11张12张13张14张15张16张17张18张19false实现Runnable接口
public class RunnableTicket { public static void main(String[] args) { //3. 创建实现类的对象 Window window = new Window(); //4. 将此对象作为参数传递到Thread类的构造器中,创建Thread类的对象 Thread w1 = new Thread(window); Thread w2 = new Thread(window); Thread w3 = new Thread(window); w1.setName("窗口1-"); w2.setName("窗口2-"); w3.setName("窗口3-"); //5. 通过Thread类的对象调用start() w1.start(); w2.start(); w3.start(); }}//1. 创建一个实现了Runnable接口的类class Window implements Runnable { //这里不需要加static private int ticket = 100; //2. 实现类去实现Runnable中的抽象方法:run() @Override public void run() { while (true) { if (ticket > 0) { try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "卖票号" + ticket--); } else break; } }}
部分运行结果:窗口2-卖票号5窗口3-卖票号2窗口1-卖票号3窗口2-卖票号3窗口1-卖票号0窗口3-卖票号-1窗口2-卖票号1//若在输出语句之前加上sleep(10),让线程进入if判断语句之后休眠10ms,则会导致下面的运行结果,出现重票和错票。一个线程进入if判断语句之后休眠了,还没有完成自减的操作,此时另一个线程也进来了,一次判断导致了两次自减,所以就会出现了重票和错票的现象。解决办法就是加个锁(同步监视器),一个线程执行过程中,不让别的线程进来就好了,下文会提供解决办法。继承方式和实现方式的联系与区别
- 比较上述两种创建线程的方式
- 开发中:优先选择实现Runnable接口的方式
- 原因:没有类的单继承性的局限性,实现方式更适合来处理多个线程共享数据的情况。
- 联系:Thread类也实现了Runnable接口 -> public class Thread implements Runnable
- 相同点:两种方式都需要重写run(),将线程要执行的逻辑声明在run()中
线程的生命周期
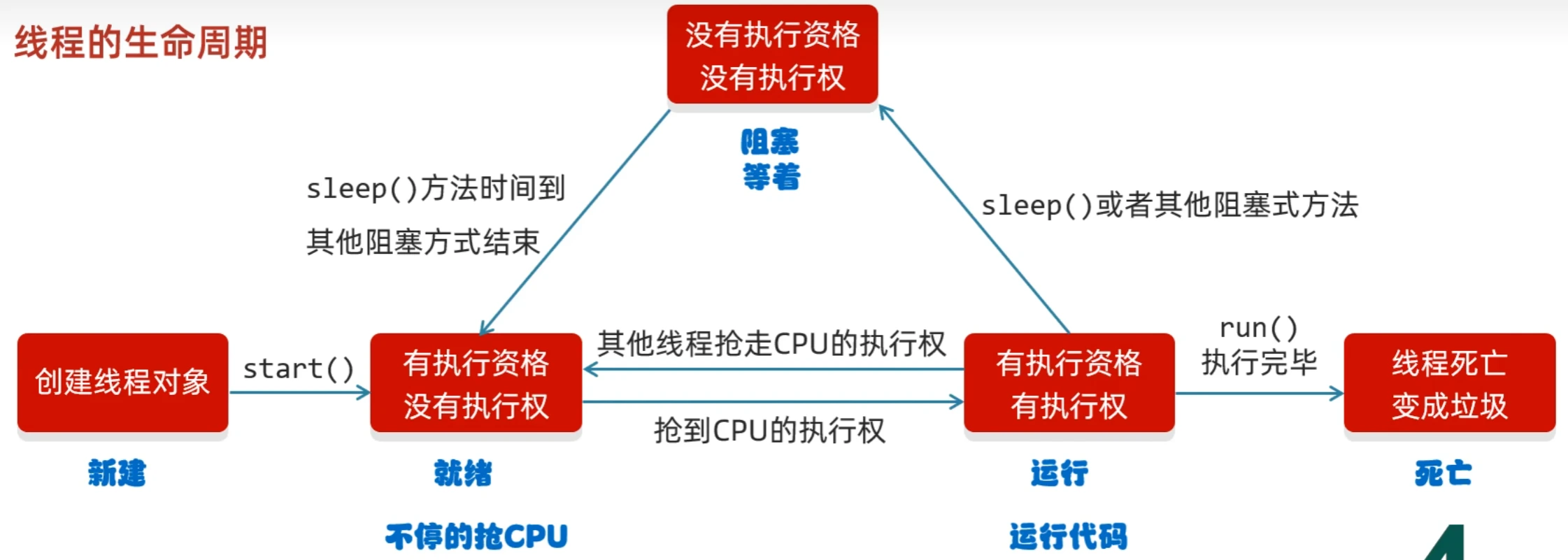
线程的生命周期
- 新建:当一个Thread类或其子类的对象被声明并创建时,新生的线程对象处于新建状态
- 就绪:处于新建状态的线程被start()后,将进入线程队列等待CPU时间片,此时它已具备了运行的条件,只是没分配到CPU资源
- 运行:当就绪的线程被调度并获得CPU资源时,便进入运行状态,run()方法定义了线程的操作和功能
- 阻塞:在某种特殊情况下,被人为挂起或执行输入输出操作时,让出CPU并临时中止自己的执行,进入阻塞状态
- 死亡:线程完成了它的全部工作或线程被提前强制性地中止或出现异常导致结束
1. 新建状态
MyThread myThread = new MyThread(); // 此时线程只是被创建,还没有任何动作 // 就像买了一辆车,但还没启动
--- 2. 就绪状态
myThread.start(); // 调用 start() 后 // 线程进入就绪队列,等待 CPU 调度 // 就像车启动了,但还在等红绿灯
--- 3. 运行状态
// CPU 分配时间片给这个线程时 // run() 方法开始执行 @Override public void run() { // 这里的代码正在运行 System.out.println("正在执行"); }
--- 4. 阻塞状态
@Override public void run() { // 情况1:人为挂起 Thread.sleep(1000); // 休眠,让出 CPU
// 情况2:等待锁 synchronized (obj) { // 等待获取锁 }
// 情况3:等待输入输出 Scanner sc = new Scanner(System.in); String input = sc.next(); // 等待用户输入 } // 阻塞时线程暂停,CPU 去执行其他线程
--- 5. 死亡状态
@Override public void run() { for (int i = 0; i < 100; i++) { System.out.println(i); } // run() 方法执行完毕 // 线程死亡,不能复用 }线程分类
Java中的线程分为两类,一种是守护线程,一种是用户线程
-
它们在几乎每个方面都是相同的,唯一的区别是JVM何时离开
-
守护线程是用来服务用户线程的,通过在start()方法前调用thread.setDaemon(true)可以把一个用户线程变成守护线程
-
Java垃圾回收就是一个典型的守护线程。
-
若JVM中都是守护线程,当前JVM将退出。
同步代码块
处理Runnable接口的线程安全
问题引入
例子:创建三个窗口卖票,总票数为100张.使用实现RunnabLe接口的方式
- 卖票过程中出现重票、错票 —-> 出现了线程的安全问题
- 问题出现的原因:当某个线程操作车票的过程中,尚未操作完成时,其他线程参与进来,也操作车票
- 如何解决:当一个线程在操作ticket的时候,其他线程不能参与进来。直到线程操作完ticket时,其他线程才可以操作ticket。这种情况即使线程a出现了阻塞,也不能被改变。
- 在java中,我们通过同步机制,来解决线程的安全问题。
//方式一:同步代码块
synchronized(同步监视器){ //需要被同步的代码 //同步是一种高开销的操作,因此应该尽量减少同步的内容。 //通常没有必要同步整个方法,使用synchronized代码块同步关键代码即可。}public class RunnableTicket { public static void main(String[] args) { Window window = new Window(); //一个实例均指向一个window对象,可以用this Thread w1 = new Thread(window); Thread w2 = new Thread(window); Thread w3 = new Thread(window); w1.setName("窗口1-"); w2.setName("窗口2-"); w3.setName("窗口3-"); w1.start(); w2.start(); w3.start();
}}
class Window implements Runnable { private int ticket = 100; //Object object=new Object(); @Override public void run() { while (true) { //synchronized (object){ synchronized (this){ if (ticket > 0) { try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "卖票号" + ticket--); } else break; } } }}
部分执行结果:
窗口3-卖票号5窗口3-卖票号4窗口3-卖票号3窗口3-卖票号2窗口3-卖票号1
可以看到已经不存在重票和错票的情况了注意事项
- 操作共享数据的代码,即为需要被同步的代码—->不能包含代码多了,也不能包含代码少了。
- 共享数据:多个线程共同操作的变量。比如: ticket就是共享数据
- 同步监视器,俗称:锁。任何一个类的对象,都可以来充当锁。要求:多个线程必须要共用同一把锁。
- 补充:在实现RunnabLe接口创建多线程的方式中,我们可以考虑使用this充当同步监视器。
//线程抢夺Cpu具有随机性,在sout打印时不同的线程在执行同一个代码,防止其他线程进入
//synchronized应写在while的内部 锁应该唯一可以是类的字节码文件 类名.class
处理继承Thread类的线程安全
public class TicketDemo { public static void main(String[] args) { Window w1 = new Window(); Window w2 = new Window(); Window w3 = new Window(); w1.setName("窗口1-"); w2.setName("窗口2-"); w3.setName("窗口3-"); w1.start(); w2.start(); w3.start(); }}
class Window extends Thread { private static int ticket = 100; //声明一个静态的obj也可以当锁// private static Object object = new Object();// synchronized (object) { //注意这里不能用this,此时的this指的是w1,w2,w3三个对象,并不是唯一的 三个 this 是三个不同的对象,三把不同的锁,无法互斥! t1 的锁 ──→ t1 能进入 t2 的锁 ──→ t2 能进入 t3 的锁 ──→ t3 能进入 // 各锁各的,没有同步效果 //这里使用的是类锁
@Override public void run() { while (true) { synchronized (Window.class) { if (ticket > 0) { try { sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "卖票号" + ticket--); } else break; } } }}
部分执行结果:
窗口2-卖票号7窗口2-卖票号6窗口2-卖票号5窗口2-卖票号4窗口2-卖票号3窗口2-卖票号2窗口2-卖票号1
可以看到已经不存在重票和错票的情况了同步方法
处理实现Runnable的线程安全问题
方式二:同步方法 如果操作共享数据的代码完整的声明在一个方法中,我们不妨将此方法声明同步的 同步的方式,解决了线程的安全问题。---好处 操作同步代码时,只能有一个线程参与,其他线程等待。相当于是一个单线程的过程,效率低。---局限性使用 synchronized关键字,可以修饰普通方法、静态方法,以及语句块。由于java的每个对象都有一个内置锁,当用此关键字修饰方法时, 内置锁会保护整个方法。在调用该方法前,需要获得内置锁,否则就处于阻塞状态。需要注意的是调用静态方法时,锁住的不是对象,锁住的是类。//修饰普通方法public synchronized void method(){
}//修饰静态方法public static synchronized int increase(){
}public class RunnableTicket { public static void main(String[] args) { Window window = new Window(); Thread w1 = new Thread(window); Thread w2 = new Thread(window); Thread w3 = new Thread(window); w1.setName("窗口1-"); w2.setName("窗口2-"); w3.setName("窗口3-"); w1.start(); w2.start(); w3.start();
}}
class Window implements Runnable { private int ticket = 100;
@Override public void run() { while (true) { if (!show()) break; } } //修饰普通方法 private synchronized boolean show() { if (ticket > 0) { try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "卖票号" + ticket--); return true; } else return false; }}
部分执行结果:
窗口1-卖票号6窗口1-卖票号5窗口1-卖票号4窗口1-卖票号3窗口1-卖票号2窗口1-卖票号1继承Thread类的线程安全问题
public class TicketDemo { public static void main(String[] args) { Window w1 = new Window(); Window w2 = new Window(); Window w3 = new Window(); w1.setName("窗口1-"); w2.setName("窗口2-"); w3.setName("窗口3-"); w1.start(); w2.start(); w3.start(); }}
class Window extends Thread { private static int ticket = 100;
@Override public void run() { while (true) { if (!show()) break; } } //修饰静态方法 private static boolean show() { //同步监视器:Window4.class// private boolean show() { 同步监视器:t1,t2,t3。此种解决方式是错误的,仍会出现重票错票 if (ticket > 0) { try { sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "卖票号" + ticket--); return true; } else return false; }}死锁的问题
public class ThreadTest { public static void main(String[] args) {
StringBuffer s1 = new StringBuffer(); StringBuffer s2 = new StringBuffer();
new Thread(){ @Override public void run() { synchronized (s1){ s1.append("a"); s2.append("1");
try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); }
synchronized (s2){ s1.append("b"); s2.append("2");
System.out.println(s1); System.out.println(s2); } } } }.start();
new Thread(new Runnable() { @Override public void run() { synchronized (s2){ s1.append("c"); s2.append("3");
try { Thread.sleep(100); } catch (InterruptedException e) { e.printStackTrace(); }
synchronized (s1){ s1.append("d"); s2.append("4");
System.out.println(s1); System.out.println(s2); } } } }).start(); }}//当第一个线程拿到s1锁的时候,休眠了0.1秒的时间内,第二个线程拿到了s2锁。当第一个线程醒了之后,需要拿s2锁,而第二个线程拿着s2锁,又需要拿s1锁,于是两个线程就僵持下去,形成死锁。(加sleep()方法只是增加发生的可能性,不加sleep()方法也有几率会发生死锁)Lock锁解决线程安全
- java.util.concurrent.locks.Lock接口是控制多个线程对共享资源进行访问的工具。锁提供了对共享资源的独占访问,每次只能有一个线程对Lock对象加锁,线程开始访问共享资源之前应先获得Lock对象。
- ReentrantLock类实现了Lock ,它拥有与synchronized相同的并发性和内存语义,在实现线程安全的控制中,比较常用的是ReentrantLock,可以显式加锁、释放锁。
- 从JDK 5.0开始,Java提供了更强大的线程同步机制——通过显式定义同步锁对象来实现同步。同步锁使用Lock对象充当。
synchronized 与Lock的异同?
- 相同:二者都可以解决线程安全问题
- 不同: synchronized机制在执行完相应的同步代码以后,自动的释放同步监视器,Lock需要手动的启动同步(Lock()),同时结束同步也需要手动的实现(unLock())
- 优先使用顺序: Lock >> 同步代码块 >> 同步方法
import java.util.concurrent.locks.ReentrantLock;
public class RunnableTicket { public static void main(String[] args) { Window window = new Window(); Thread w1 = new Thread(window); Thread w2 = new Thread(window); Thread w3 = new Thread(window); w1.setName("窗口1-"); w2.setName("窗口2-"); w3.setName("窗口3-"); w1.start(); w2.start(); w3.start(); }}
class Window implements Runnable { private int ticket = 100; //1.实例化ReentrantLock private ReentrantLock lock = new ReentrantLock(); @Override public void run() { while (true) { try { //2.调用锁定方法:lock() lock.lock(); if (ticket > 0) { try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + "卖票号" + ticket--); } else break; } finally { //3.调用解锁方法:unlock() lock.unlock(); }
} }}线程通信
方法
涉及到的三个方法: wait():—旦执行此方法,当前线程就进入阻塞状态,并释放同步监视器。 notify():一旦执行此方法,就会唤醒被wait的一个线程。如果有多个线程被wait,就唤醒优先级高的那个。 notifyALL():—旦执行此方法,就会唤醒所有被wait的线程。 说明:
- wait(),notify(),notifyALl()三个方法必须使用在同步代码块或同步方法中。
- wait(),notify(),notifyAlL()三个方法的调用者必须是同步代码块或同步方法中的同步监视器。否则,会出现ILLegaLMonitorstateException异常
- wait(),notify(),notifyAll()三个方法是定义在java.Lang.object类中。
public class ThreadTest { public static void main(String[] args) { Number number = new Number(); Thread t1 = new Thread(number); Thread t2 = new Thread(number); t1.setName("线程一:"); t2.setName("线程二:"); t1.start(); t2.start(); }}
class Number implements Runnable { private int num = 1; @Override public void run() { while (true) { synchronized (this) { //2.唤醒被wait的线程,从而达到两个线程交替运行的效果 notify(); if (num <= 100) { try { Thread.sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } System.out.println(Thread.currentThread().getName() + num++); try { //1.使得调用如下wait()方法的线程进入阻塞状态,并释放锁 wait(); } catch (InterruptedException e) { e.printStackTrace(); } } else break; } } }}sleep和wait的异同
-
一旦执行方法,都可以使得当前的线程进入阻塞状态。 不同点
-
两个方法声明的位置不同:Thread类中声明sleep() , Object类中声明wait()
-
调用的要求不同:sleep()可以在任何需要的场景下调用。 wait()必须使用在同步代码块或同步方法中
-
关于是否释放同步监视器:如果两个方法都使用在同步代码块或同步方法中,sleep()不会释放锁,wait()会释放锁。
生产者消费者
初识
生产者(Productor)将产品交给店员(Clerk),而消费者(Customer)从店员处取走产品,店员一次只能持有固定数量的产品(比如:20),如果生产者试图生产更多的产品,店员会叫生产者停一下,如果店中有空位放产品了再通知生产者继续生产;如果店中没有产品了,店员会告诉消费者等一下,如果店中有产品了再通知消费者来取走产品。
这里可能出现两个问题:
- 生产者比消费者快时,消费者会漏掉一些数据没有取到。
- 消费者比生产者快时,消费者会取相同的数据。
分析:
-
是否是多线程的问题? 是,生产者的线程,消费者的线程
-
是否有共享数据的问题? 是,店员、产品、产品数
-
如何解决线程的安全问题? 同步机制,有三种方法
-
是否涉及线程的通信? 是
class Clerk { private int productCount = 0; public synchronized void InProduction() { if (productCount < 20) { System.out.println(Thread.currentThread().getName()+"正在生产第" + (++productCount) + "个产品"); notify(); } else { try { wait(); } catch (InterruptedException e) { e.printStackTrace(); } } }
public synchronized void SaleProduct() { if (productCount > 0) { System.out.println(Thread.currentThread().getName()+"正在购买第" + (productCount--) + "个产品"); notify(); } else { try { wait(); } catch (InterruptedException e) { e.printStackTrace(); } } }}
class Producer extends Thread { private Clerk clerk;
public Producer(Clerk clerk) { this.clerk = clerk; }
@Override public void run() { while (true) { try { sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } clerk.InProduction(); } }}
class Customer extends Thread { private Clerk clerk;
public Customer(Clerk clerk) { this.clerk = clerk; }
@Override public void run() { while (true) { try { sleep(10); } catch (InterruptedException e) { e.printStackTrace(); } clerk.SaleProduct(); } }}
public class ThreadDemo { public static void main(String[] args) { Clerk clerk = new Clerk(); Producer producer = new Producer(clerk); Customer customer = new Customer(clerk); producer.setName("生产者-"); customer.setName("消费者-"); producer.start(); customer.start(); }}网络编程
反射
支持与分享
如果这篇文章对你有帮助,欢迎分享给更多人或赞助支持!
评论区
音乐
暂未播放

